Look up ‘DITA’ in the Acronym Dictionary and you’ll find 6 different definitions. Even knowing what the letters stand for (*) doesn’t put us much closer to understanding what it is. But it does seem to communicate that it is:
- Esoteric
- Technical and
- Most likely difficult to explain.
Nevertheless, if you are an information professional, you should be paying attention to this evolving standard for content reuse. It’s not that complex; and the business value can be significant.
Business Benefits of Reuse
Content reuse is a good business justification – especially for technical documentation (DITA’s original home) where the mechanics and modeling really lend themselves to this approach. Structured content authoring can reduce the headcount in a technical documentation organization that needs to produce documentation in a variety of formats and for many different versions of a product. Standard safety information or set up instructions are authored in component models because the boilerplate does not vary and it has to be in every product, language and device. However, documentation does not provide competitive advantage and taking out some headcount from a technical publications department may not always be feasible or worth the significant up-front investment. Documentation is a necessary cost and does not make the product, brand or organization stand out in the marketplace.
What is propelling DITA forward is that effective content reuse can translate into new revenue opportunities.
Product Agility, Unsupervised Support, Marketing Responsiveness and Knowledge Access
If we look at reuse of content and efficiency of content publishing from the perspective of speeding time to market, increasing product marketing agility or providing differentiated offerings that are more responsive and personalized, now we are looking at enhancements and capabilities that can truly provide competitive advantage and help an organization stand out and compete more effectively.
Unsupervised support can benefit greatly from this kind of approach. Self-service documentation might be used to deflect help desk or call center calls or to improve the effectiveness of customer support resources – and dramatically improve customer satisfaction and loyalty. Being able to tailor a marketing campaign quickly and efficiently can help win market share from the competition based on feedback through social media channels or when there is another time sensitive opportunity in the marketplace. Responsiveness to change and rapid testing and evolution of messaging can provide a significant competitive advantage. There is also speed to market for new product launches, especially when dealing with a complex distribution channel.
Field service documentation is also an excellent place to provide benefits of not just content reuse but also information access. When developing component models for content, the access scenarios can be very specific and assist in faster troubleshooting and knowledge in problem specific contexts. Some field service documentation is quite large and extensive and the information needs to be broken up into more bite sized pieces to enable more and precise search and retrieval, to in turn enable faster troubleshooting.
Speed to market can be significantly improved through content syndication – a special form of reuse. Manufacturers of mobile devices work through carriers like Verizon who are the distribution channels. Content from an engineering group can be syndicated through to support who can in turn syndicate their content through marketing and through distribution partners. In other words, a change in product support or technical specifications or troubleshooting content can be pushed off through channels within hours through automated and semi-automated updates instead of days or weeks with manual conversions and refactoring of content. The following diagram illustrates this scenario:
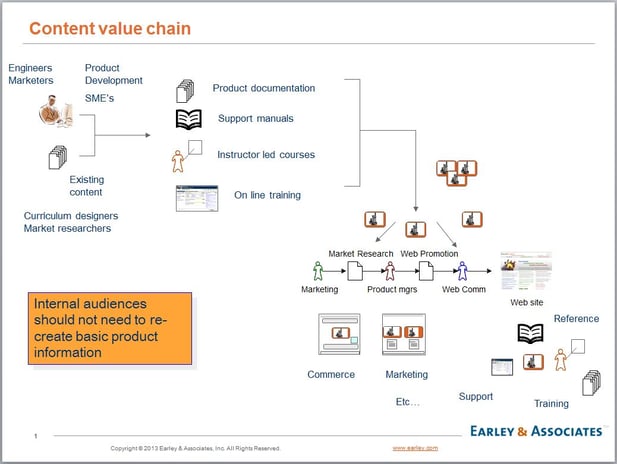
Content embodies value in an organization. It is the lifeblood of the enterprise and transfer and flow of that content is facilitated through content processes and content engineering. Consider the engineering of single source authoring as a way to speed the flow of value through the enterprise. When people can locate and reuse information, they are saving time and eliminating non value-added activities.
What is the value of re-keying data? Or rewriting content? If, instead, that content can flow with automated conversions, the speed of value to market is increased. Information in the consumer’s hands is information that can be used to sell a product or solve a problem or meet a need or produce some kind of value. Content processing is the machinery that moves that content into the hands of those who need it.
So What is DITA?
The idea behind DITA is that one can piece together components of content and develop a complete document or page from those components. In order to do so, we need the components themselves – these can be in very small pieces – like single procedures, concepts, or bits of reference information – and something that tells us what components go where. The first is the core component of DITA – the “topic” and the second is the structure for a DITA document or the “map”. It sounds very simple and it really is – however, complex and interesting things can be developed from simple components. One really nifty bit of componentry is called “content profiling” and is the mechanism by which different experiences can be created within a single piece of content so that it can ‘adapt’ to different audiences, roles, devices, product, platforms, or really anything that can be described with metadata.
If we structure information correctly, it is possible to create a piece of content and then reuse that content in many different contexts. Information becomes a component and deliverables (like publications or websites) can be created, and more quickly updated, with these modular bits of information in a more efficient, cost effective way. It’s a very simple concept and in fact, all web sites use this reuse principle to one degree or another, regardless of whether or not they use DITA. Take a standard header and footer, or consistent navigation – these are simple examples of content reuse.
DITA provides an extensible framework enabling organizations to address content reuse in a consistent scalable manner. It enables content to be developed in many departments by experts and then that content is reused for various applications. The diagram that follows illustrates this:
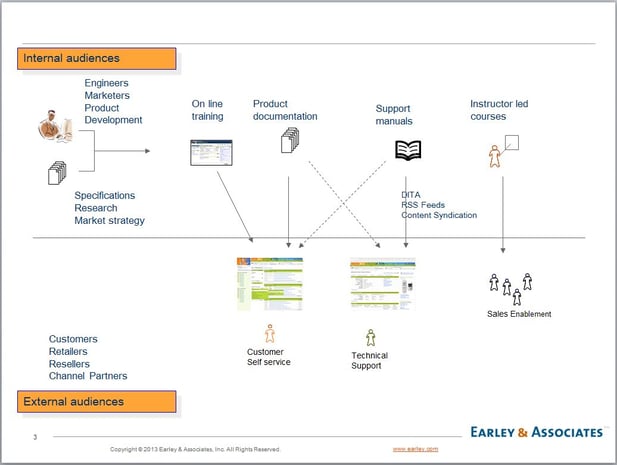
This slide illustrates a number of concepts – master content with consistent metadata travels through the various content processes in order to produce different outputs. The “existing content” can be authored in a reusable content model that would allow that information to be assembled into multiple outputs for various platforms, or that content might be broken up for reuse in downstream processes. Online training materials frequently contain content from support manuals. Instructor led courses can be developed with product documentation references. Any of these outputs could be considered as inputs for the next sets of processes – marketing, product positioning, promotions, etc., or exposed through the company web sites or those of partners. With the appropriate technologies, information architecture, and information development practices in place, reuse is to content as “master data” is to databases.
(*) Darwin Information Typing Architecture (back to top)