Every significant technology wave arrives with a story that makes the complex feel inevitable. Enterprise search promised a single interface that would organize everything. Cloud computing offered to make infrastructure complexity disappear. Today's dominant narrative holds that autonomous AI agents can reason across systems, plan multi-step workflows, and execute decisions with minimal human involvement. Watch a well-staged demo and the story is convincing. An agent queries multiple systems, retrieves documents, summarizes content, updates records, and completes workflows end-to-end. It looks coordinated, responsive, and capable.
Then those agents get deployed inside real organizations.
They surface contradictory answers. They misinterpret policy. They retrieve outdated documents with confidence. They fail in ways that are difficult to detect because the outputs sound fluent and authoritative until the consequences show up downstream. This is not primarily a model problem. The models are capable. The problem is information architecture — or rather, the absence of it.
Why Agents Fail in Real Enterprise Environments
Agents don't operate in clean, curated environments. They operate inside enterprises shaped by decades of accumulated systems, inconsistent metadata, overlapping vocabularies, and undocumented assumptions about what is authoritative and what isn't. Human employees survive in this environment because they carry context in their heads. They know which version of a policy is current, which report is "directionally right" despite not being updated, and where the official process ends and the informal one begins. Agents cannot infer any of this unless it has been explicitly encoded.
Large language models do not possess organizational intuition. They operate by predicting statistically likely continuations of text. When the enterprise environment is fragmented or ambiguous, the model fills gaps with plausibility. In regulated industries, plausibility without traceability is not intelligence — it is liability. The particular danger of this failure mode is that the answer does not look wrong. It reads confidently, aligns with expectations, and only reveals its error when consequences emerge downstream.
This is why the cycle of agentic AI initiatives is so consistent and so frustrating. A pilot succeeds in a bounded environment, creating confidence. Broader deployment exposes semantic inconsistencies that the pilot never encountered. Trust erodes, adoption slows, ROI is questioned, and the initiative is reframed or quietly absorbed into the next program under a different name. The speed and visibility of failure has accelerated compared to previous technology waves. Agents operate at conversational speed, feel personal, and when they produce wrong answers, users experience that failure immediately. A misleading dashboard can be ignored. A confident but incorrect agent cannot.
Information Architecture as Containment Infrastructure
The phrase "No Agents Without IA" is not a slogan. It is a diagnostic. Information architecture does not eliminate error from AI systems — it contains it. It provides the scaffolding that constrains intelligence to operate within known boundaries rather than improvising across uncertainty.
If an organization cannot clearly define its core entities, align terminology across systems, establish content ownership, or enforce metadata discipline, deploying agents will not fix those problems. It will expose them. Conversely, organizations that have invested in information architecture often discover that agentic capabilities emerge naturally from that investment: retrieval improves, generation stabilizes, orchestration becomes predictable. The model did not change. The information environment did.
The enterprises that treat agents as a source of intelligence rather than a multiplier of existing structure will experience short-lived excitement followed by extended disappointment. Those that treat agents as amplifiers — capable of scaling whatever structure already exists, for better or worse — will build systems that are both measurable and trustworthy. The difference is not ambition or budget. It is architecture.
Search as the Perceptual Layer of AI
One of the most consistent findings from real enterprise AI deployments is that the systems producing sustained value are not primarily agent-led — they are search-led. This observation is counterintuitive given the current emphasis on autonomous workflows and reasoning agents. But inside organizations where AI is generating measurable outcomes, search functions as foundational infrastructure, not as a legacy interface.
Generative AI fundamentally changes the role that search plays. When AI systems generate answers, recommendations, or actions, the quality of those outputs is directly constrained by what the system retrieves. Retrieval becomes perception. If the system encounters the wrong information, it reasons incorrectly regardless of how sophisticated the underlying model is. This is precisely why retrieval-augmented generation succeeds when it works and fails when it doesn't. The model is not the differentiating variable. The retrieval pipeline is.
In customer support environments, well-designed search retrieves validated procedures, policies, and known-issue documentation — the language model does not invent answers but explains and contextualizes what was retrieved. In field service and manufacturing, search grounded in structured product metadata drives diagnostic guidance with precision. In compliance and regulatory contexts, search enforces provenance before synthesis, making generation an interpretive layer rather than a creative one. Across all of these, the same principle holds: search is the perceptual system of enterprise AI. What the agent can see determines what it can reason about.
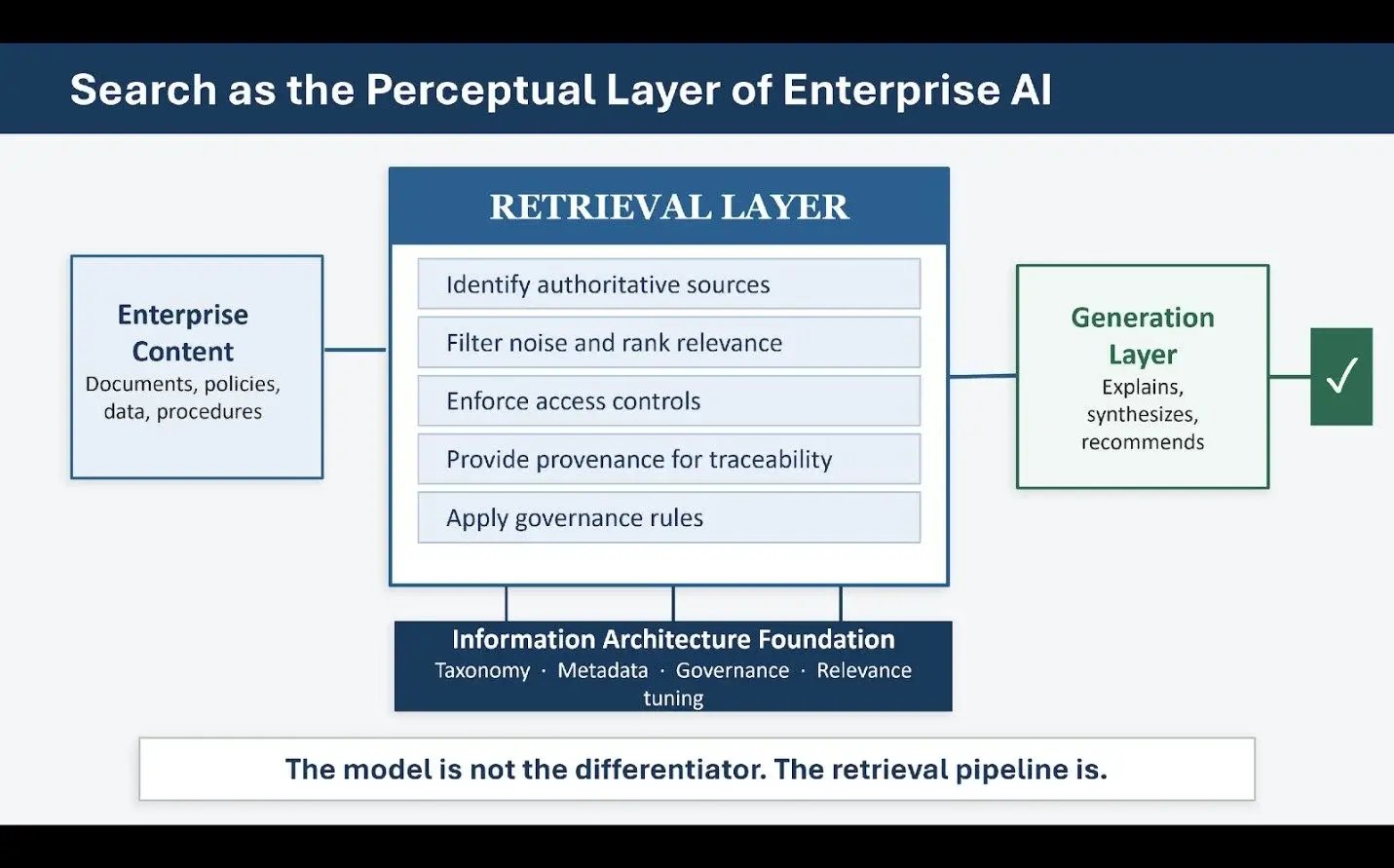
Figure 1: Search as the Perceptual Layer of Enterprise AI
Why Search Maturity Predicts AI Readiness
Organizations that invested early in taxonomy, metadata discipline, and search relevance tuning now find themselves structurally ahead of organizations that deferred that work. The components that make search trustworthy are the same ones that make agents reliable. Taxonomy determines how content is grouped and distinguished. Metadata encodes context that raw text cannot reliably convey. Relevance tuning aligns retrieval with actual user intent rather than keyword coincidence. Governance ensures that what is retrieved is current, authoritative, and appropriate for the task.
Together, these elements form the substrate on which intelligence operates. When any of them are weak, generative systems compensate by guessing — prompts grow longer and more complex, human review increases, exceptions multiply, and the system becomes brittle and expensive to maintain. When they are strong, downstream complexity collapses. Prompts simplify, agents become composable, governance becomes tractable, and the system can evolve incrementally rather than requiring constant emergency intervention.
The practical implication is that the right question for enterprise leaders to ask is not "Where can we deploy agents?" but rather "Where do we have retrieval discipline strong enough to support reasoning?" The answer often surprises organizations. Their most AI-ready assets are frequently not their newest systems but the ones where information architecture work has already been done.
It is also worth recognizing that search and generation are not sequential — they form a feedback loop. Retrieval informs generation, user interaction informs relevance, and improved relevance strengthens retrieval over time. In a well-designed agentic enterprise, the agent does not search indiscriminately. It acts within a curated semantic frame that search has already established. Search, in this model, is no longer about finding things. It is about shaping the information reality within which machines operate.
The Economics of Structure in Agentic Systems
As organizations move from experimentation to operational deployment, the economic logic of information architecture becomes impossible to ignore. The costs associated with weak architecture are real but often distributed in ways that make them difficult to attribute directly. When content is inconsistently described, retrieval precision drops. To compensate, prompts become longer and more complex, increasing processing costs and latency while introducing more surface area for error. As confidence in outputs declines, human review increases, manual intervention becomes routine rather than exceptional, and the business case for automation quietly dissolves.
Strong information architecture inverts this equation. When entities are clearly defined, metadata is consistent, and content ownership is explicit, retrieval becomes precise. Precise retrieval reduces prompt complexity. Simpler prompts lower cost and improve explainability. Improved explainability increases trust, and increased trust reduces the need for human intervention. The result is not just better AI — it is cheaper, more predictable AI that compounds in value over time.
This leads to one of the most important and most frequently overlooked insights in the current agent conversation: agents are not sources of intelligence. They are multipliers. They amplify whatever structure already exists. Ambiguous definitions produce amplified ambiguity. Weak governance produces amplified risk. Outdated content spreads at agent speed rather than human speed. Conversely, when structure is strong, agents amplify coherence, consistency, and operational efficiency.
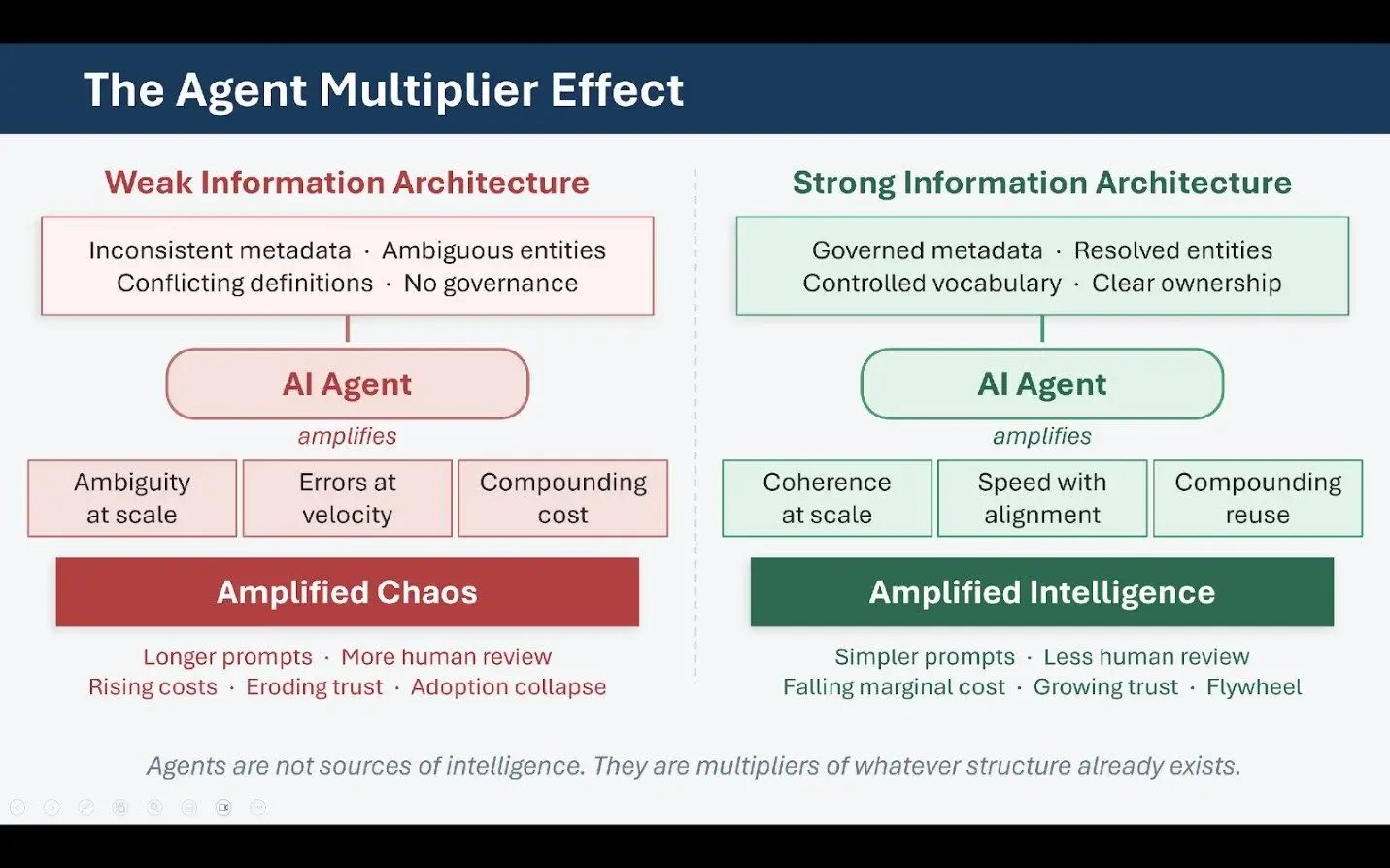
This multiplier dynamic explains why two organizations using the same foundation model and the same orchestration framework can experience opposite outcomes. The visible layer — the interface, the workflow, the agent logic — can be replicated. The invisible layer of semantic foundations that makes those agents reliable cannot. It has to be built.
Architectural Debt and the Case for Bounded Autonomy
The scaling failure pattern in agentic AI is often described as a technical problem. It is more accurately described as an architectural debt problem made newly visible. In traditional enterprise systems, semantic inconsistency could persist for years without immediate consequence because human employees compensated through experience and informal knowledge. Agents do not compensate. They execute. That execution pressure forces organizations to confront questions they have deferred for decades: What is the authoritative definition of a customer? Which policy version applies? Who owns this content? When should it be retired? These are organizational questions, not technical ones — they cut across silos and require governance decisions that no model can make on its own.
From an investment perspective, this reframes information architecture work as capital expenditure rather than operational overhead. Architecture done once reduces cost and risk across every downstream AI use case. Architecture deferred becomes a tax that compounds as the scale of automation increases. And the error velocity problem is asymmetric: a human making a judgment error affects a bounded number of cases; an agent making the equivalent error can propagate it across thousands of transactions in minutes.
This does not argue against automation. It argues for bounded autonomy — agents that operate within clearly defined domains, escalate uncertainty, and defer when confidence thresholds are not met. Information architecture enables this calibration by providing the signals agents need to know when they are operating within safe bounds and when they are not. Well-architected systems do not pursue maximum automation. They pursue appropriate automation: reliable within defined scope, transparent about its limits, and designed to grow that scope incrementally as trust is earned.
Organizations that understand this invest differently. They fund taxonomy and metadata work alongside model experimentation. They treat governance as an enabler rather than an obstacle. They measure retrieval quality — not just model accuracy. And they staff semantic stewardship roles alongside prompt engineers and ML practitioners. Over time, these investments compound: each new agent is easier to deploy, each new use case builds on shared foundations, and intelligence becomes reusable rather than bespoke.
Agents do not eliminate the need for information architecture. They make its absence untenable. In the economics of the agentic enterprise, structure is not overhead. It is leverage.
This is Part 1 of a two-part series. Part 2 examines how semantics and knowledge graphs address the limits of text-centric AI, and how governance and operating models must evolve to enable safe autonomy at enterprise scale.
Read the original version of this article on VKTR.