Information managers need to be able to quantify the value of information curation, because otherwise justifying its cost can be difficult. Proper information and content curation is a key enabler for collaboration, data quality, accessibility, adaptability, and usability. All are great capabilities, but can we know for sure how much are they worth? The answer is yes: We can calculate the ROI on curation efforts and in this article, I'm going to show you how to so by using common examples present in many industries.
So, is an information and content curation effort worth US$100,000 or $10,000,000? What's a reasonable annual spend? Let me show you how to determine this with confidence.
What is curation?
Information and content curation consist of the intentional information management efforts that improve the desired data and knowledge outcomes. For example, proper curation of website search features improves the quality, experience, and reliability of search. To measure ROI, we focus on the outcomes more than the actions that produce them, but typical curation solutions include data modeling and cleansing, process optimization, taxonomy and information architecture development, tools selection and synchronization, content strategy, automation, and governance. These curation solutions vary widely in scope and effort, though, when successfully completed and maintained, can result in a tighter, more efficient information retrieval experience for customers and employees alike.
The outcomes model
Measurability requires detectable outcomes. Instead of trying to isolate and measure the value of a "taxonomy," we attempt to measure the impact of "taxonomy-like efforts" (i.e. curation) on the business. We don't need to get the number exactly right. Any estimates that improve upon our current knowledge can provide value, and because they are estimates, we acknowledge they may not be perfect to start out with, but certainly can be improved over time with proactive and reproducible research.
Consider any business action or activity that users might need to repeat until they get it right: performing a content search, completing a design, building a document, or researching a decision. Our algorithm describes this as a simple loop: (1) perform the action, (2) succeed or fail, (3) try again or quit. To calculate the cost of this loop we assign costs to each one: (1) the cost of performing the action, (2) the cost of failure, and (3) the cost of quitting.
Even in an ideal situation – in which the action is performed once and success is immediately achieved – still incurs a cost, though it will cost lest in a less than ideal scenario. In this ideal situation, an action can still be improved by reducing the cost of the action itself (in other words, speeding it up).
In a more realistic situation, some users try not an action just once, but two, three, or four times before they actually achieve their goal. Some users, either disheartened by the experience or lacking in wherewithal, quit without ever achieving their goals. Perhaps more unfortunately, some users mistakenly believe they've succeeded and quit without realizing their error until later.
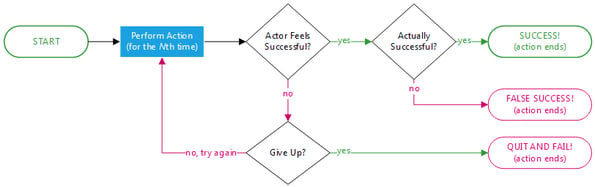
The obvious costs - an illustration
In the simplest interpretation, three costs are associated with this model: the cost of performing the action, and two different failure costs. To illustrate these, let's consider the simple example of someone trying to log into an account. The performance cost is often measured in time. How long does it take someone to type their account name and password into a dialog? We can actually measure this. When I use challenging passwords, I need about ten seconds to enter in my credentials. If I mistype something, I'll probably try again, but each additional attempt will take longer as I type more carefully or rethink what I know.
However, one of two things will happen after some number of tries. Either I'll give up and abandon the task entirely and be forced to incur the cost of trying something else; for example, using the phone to speak to a customer service representative, resetting my login credentials using the tool’s “change password” wizard, and/or taking the frowned upon action of using someone else's account. Else, I'll trust myself one too many times (thereby creating a false positive) and lock myself out of my account after too many failed attempts.
In this example, most of my costs are easily measurable as time spent or wasted on attempting to complete the task. Depending on the situation, I could spend upwards of 15 minutes talking to technical support on the phone for help logging in to the system or spend even more time speaking to a customer service representative to assist with the information retrieval task at hand. There might also be money or social costs if I can't accomplish my goal: paying fees or penalties, losing “quick win” opportunities, switching service providers, embarrassment, and other realized risks like lost wages or lost data.
In addition, the company whose application is asking me for a password also experiences costs. The time a customer spends retrying a task like logging in might not seem that important since they’re not the ones suffering. However, the company certainly spends money on staffing their technical support team, loses profit when customers quit attempting to login to or search for content on its site, and maybe suffers some realized risk around account theft.
You can see that this model has near-universal applicability: any action as defined, any number of repetitions of that action, and any number of defined success and failure outcomes. This said, let's look at a specific example close to the hearts of many information managers: search content quality.
Case study: search content quality
Assume that employees at Acme perform 100,000 intranet searches every business day of the year. Despite recent IT initiatives, search is still slow and clunky, and the metadata are pretty bad. It takes 10 seconds for a user to perform a search, and often another 10 seconds for the user to browse and interpret the results. The search results could definitely be better too, seeing that there’s only a 60% likelihood that the first page provides what the user wants.
The company observes that half of its employees quit using the intranet search tool after a third failure, and everyone else quits by the fourth attempt. Meanwhile, the two biggest quality “gotchas” are version control and indexing speed: Because the search index is only updated overnight and not in real-time, documents aren't available until the day after their creation. As we all know, old versions of a document often look a lot like current versions, especially if the only differences between the two consist of a few value changes. This said, let’s say 1% of the time people errantly grab an outdated copy of a document or content when there actually exists something more current. Also, folks will completely miss any document or piece of information that has not yet hit overnight re-indexing, meaning the newest documents published to the intranet aren’t available for search retrieval until tomorrow.
How does this translate into money? Acme employees spend over 22,000 hours a year using search; at $30 an hour per employee, Acme spends about $650k on search time, which is over and above any technology costs at the company. At the same time, intranet search fails over 6000 times per day and there’s at least 450 times every day that someone gives up searching for newly published documents in frustration. For simplicity, let's say that when an employee gives up, the company loses an additional $30. Unnecessary calls for help, rework due to work based on outdated information, and the resulting project delays make up this loss. Additionally, remember that 1% of searches retrieve the wrong document; this alone might quadruple the rework cost to $120.
So our total annual costs now include $650k in search time, $3.4M from employees who give up, and a bonus $2.9M penalty from working with bad documents. In total, Acme spends $6.9M every year because of the current suboptimal search situation.
And we're not even finished.
The hidden costs
The negativity that is generated by failure of any kind has a cumulative effect. It can impact relationships among companies, employees, customers, and vendors. A bad user experience will cause customers to shop elsewhere, employees to take shortcuts that escalate costs and losses (perhaps an employee uses a coworkers login credentials to access a repository that’s off-limits to their department), and employee morale and retention to suffer. These problems can further cascade as customers and employees go to friends and social media platforms to share their negativity and lure yet more people away.
When these problems grow sufficiently large, the company is forced to spend yet more money to repair and enhance systems, processes, and its own relationships and reputation. And underneath everything there is always the actuarial cost of extreme risk realization, when a highly unlikely but catastrophic result occurs: legal action, brand destruction, or worse. These extreme situations are discussed constantly among governance and compliance professionals, even as recent European privacy regulations have raised the stakes even more.
In our search example above, where 1% of searches retrieve the wrong document (a conservative estimate), it's not hard to imagine how an error might end up in a customer-facing document, which could in turn lead to client loss. For instance if Acme regularly posted to its intranet customer pricing contracts consisting of daily contractual costs for the customer, an Acme employee has a good chance of sending the customer yesterday’s customer pricing contracts. Even if only 1 in 10,000 such errors adversely affect Acme's customer base or damages its reputation, remember that version control errors are happening 96 times per day. In an average year, Acme's brand will take two very big hits. Depending on the nature and fragility of Acme's business, the $6.9M spend we calculated earlier might be only a small fraction of what Acme really needs to consider.
Finding the right curation solution
Having estimated the cost of Acme's search experience, we can look for opportunities to invest in improvement and enhance the overall experience. There are a number of great places to start:
- Reduce search time from 20 seconds to 10 seconds. Savings: $330k/year
- Increase search quality from 60% to 80%. Savings: $3M/year
- Reduce false positives from 1% to 0.1%: Savings $2.6M/year (not including the 90% reduction in reputation hits)
- All of the above: $6M/year
If a company chooses to move forward on all of the above options and saves $6M annually, investing just a fraction of this in improved curation could produce a really good ROI.
So ask yourself of your enterprise – If you had a better idea of how much time and effort your company is wasting on poorly curated information, would you start taking steps to improve your information management and provide customers and employees a greater content and information experience? Give us a call. We can plug your numbers into a case-by-case model and make some rational suggestions on how to start better curating your information and, perhaps more importantly, start saving immediately.
Need help with your own transformation program? Lay the foundation for your organization’s success with our Digital Transformation Roadmap. With this whitepaper, assess and identify the gaps within your company, then define the actions and resources you need to fill those gaps.