Navigation taxonomy serves as the discovery backbone enabling customers to locate products they seek for research or purchase. Implementing taxonomy demands adherence to proven practices ensuring maximum efficiency while supporting exceptional user experiences. The fundamental principle remains simple yet critical: products customers cannot locate will never convert to sales. Effective navigation taxonomies achieve this through intuitive organization, concise structures, and operational efficiency.
Principle One: Separate Classification from Filtering
A persistent taxonomy anti-pattern involves embedding attribute values or product specifications directly into category labels—a practice known as attribute stuffing. Consider sweater shopping where categories subdivide by material: Wool Sweaters, Cotton Sweaters, Cashmere Sweaters. Customers interested in comparing all sweater styles must navigate multiple separate categories. When material composition doesn't represent the primary differentiator driving customer decisions, this fragmentation creates frustration rather than facilitating discovery. Material attributes function more effectively as filters applied at the category level, allowing customers to view complete product ranges then narrow selections according to their specific criteria.
The diagram below illustrates another manifestation of this problem. Orientation attributes—Horizontal, Right Angle, Vertical—appear embedded within taxonomy structure itself. This forces customers into pre-filtered product subsets before they've determined whether orientation matters to their selection process. It injects unnecessary noise into the taxonomy architecture. Optimal taxonomies maintain simplicity and conciseness enabling rapid category scanning. This noise proliferates both vertically through hierarchy depth and horizontally across sibling categories. The taxonomy unnecessarily extends to three levels when two-level click hierarchy would suffice.

The superior approach employs is-ness principles within taxonomy construction—organizing by what products fundamentally are rather than specific attributes—while providing filters enabling customers to refine results according to personally relevant criteria. This pattern respects customer agency in selection processes rather than imposing predetermined filtering logic.
Principle Two: Optimize Hierarchy Depth and Breadth
Maintaining taxonomy conciseness and efficiency manifests through multiple structural decisions. Single-product categories should be avoided when logical grouping opportunities exist. Frequently, these singleton categories represent parts or accessories related to primary categories within particular taxonomy branches. Accessories consolidate effectively into unified groups, improving navigational efficiency. Sibling categories lacking coherent relationships with peers merit relocation to independent branches or repositioning within more semantically appropriate branches.
The example below reveals an Antifreeze Cooling System category interspersed with Hoses and various small component parts. Its presence disrupts categorical coherence. This particular taxonomy segment could simplify to Hoses and Hose Accessories categories, potentially adding another hierarchical layer beneath Hoses if product differentiation warrants granularity.
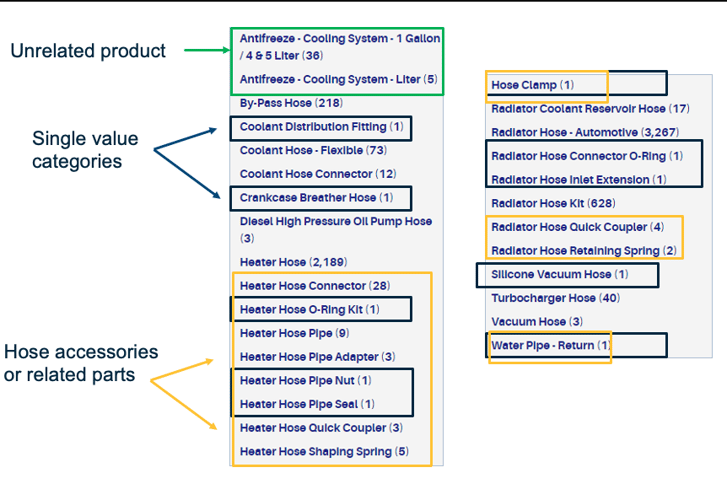
Structural optimization considers both vertical depth and horizontal breadth. Excessively shallow taxonomies force customers to evaluate overwhelming numbers of options simultaneously. Excessively deep taxonomies demand too many navigation clicks before reaching product-level content. The optimal balance depends on catalog size and product diversity, but general guidance suggests minimizing required clicks while ensuring each category level presents manageable option quantities—typically between three and fifteen child categories per parent, though exact numbers vary based on overall taxonomy scope and top-level category counts.
Incremental node naming—progressively increasing category specificity as users descend hierarchy levels—reinforces confidence that chosen pathways lead toward desired products. As customers encounter more precise product groupings deeper in the tree, specificity increases validate navigation decisions, reducing abandonment from pathway uncertainty.
Principle Three: Eliminate Ambiguous Catchalls
The final principle addresses taxonomy patterns undermining discoverability: junk drawer categories bearing ambiguous labels including Other, Miscellaneous, More, Additional Products, and similar vague descriptors. These taxonomic black holes provide no indication of contained products, leading customers to ignore them almost universally. Products relegated to these categories experience dramatically lower conversion rates compared to properly classified counterparts.
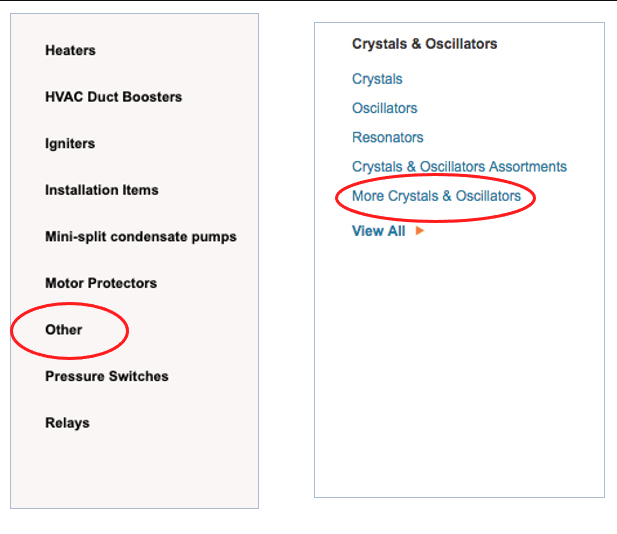
Junk drawers emerge through multiple failure modes. Sometimes new product introductions lack obvious existing categories, and perceived modification effort discourages taxonomy expansion. Other times, secondary products or edge cases get dumped into catchalls rather than receiving appropriate classification attention. Occasionally, taxonomists create these categories intending temporary placement but they persist indefinitely as permanent repository chaos.
Robust product onboarding governance prevents junk drawer proliferation. Processes should mandate proper categorization for every incoming product, including taxonomy modification when genuinely novel products require accommodation. When customers venture into Other rabbit holes seeking specific products and emerge empty-handed, frustration compounds. Navigation taxonomies aspire toward intuitive organization; junk drawers systematically undermine this objective.
Validation Through Testing
These principles provide foundational guidance for taxonomy construction and maintenance. However, theoretical soundness requires validation through empirical testing. Taxonomy testing methodologies flag problematic navigation areas before they significantly impact conversion rates. Testing approaches include:
Internal Store Walks: Select random product samples, adopt customer personas reflecting different experience levels and decision-making needs, then attempt locating those products through navigation alone. Document friction points, confusion moments, and successful pathways. Multiple team members should conduct independent walks to identify consistent patterns versus idiosyncratic difficulties.
User Testing Instruments: Specialized taxonomy testing tools enable structured evaluation with both internal and external participants. These instruments present specific findability tasks, measuring success rates, navigation time, confidence levels, and pathway selections. Data aggregated across representative user samples reveals whether taxonomy structure aligns with customer mental models or creates systematic obstacles.
Analytics Integration: Post-launch monitoring through web analytics identifies category-level performance disparities. Metrics including category traffic, conversion rates, bounce rates, and cross-category navigation patterns reveal where taxonomy succeeds versus where customers struggle. Combining quantitative analytics with qualitative testing feedback produces comprehensive understanding of taxonomy effectiveness.
The Conversion-Architecture Connection
Taxonomy represents more than organizational convenience—it directly impacts revenue performance. Customers accessing e-commerce sites arrive with varying levels of product knowledge and purchase intent certainty. Some know precisely what they need and search directly for it. Others enter exploration mode, browsing to understand available options before refining selections. Many users alternate between search and browse within single sessions, often searching broadly to reach category levels then using faceted filtering to narrow choices.
Effective taxonomy architecture supports both behavioral modes seamlessly. It enables confident navigation for knowledgeable customers while providing logical discovery pathways for browsers still defining requirements. It surfaces products where customers intuitively expect them rather than burying items in unexpected locations. It respects customer time by minimizing clicks and reducing cognitive load required for product location.
Organizations investing in taxonomy quality reap measurable returns through improved findability driving higher conversion rates, reduced customer frustration lowering abandonment, and enhanced brand perception from superior user experiences. Conversely, neglected taxonomies create compounding friction—each obstacle pushing more customers toward competitor sites offering better navigation experiences.
Taxonomy work demands ongoing attention rather than one-time effort. Product catalogs evolve, customer needs shift, competitive landscapes change, and industry terminology develops. Regular taxonomy reviews, continuous testing, and responsive refinement ensure navigation structures maintain effectiveness as contexts transform. The organizations treating taxonomy as strategic asset rather than technical afterthought position themselves for sustained e-commerce success.
Note: This article originally appeared on the Magnitude Software blog and has been revised for Earley.com.