There are many manufacturers who have started to take the leap forward in the digital space, but there are still a great number who rely solely on their distributors to manage their product data. We are going to look at 4 key reasons why its so important that manufacturers own their product and dedicate the time and resources to build it out.
1. Manage product data and assets centrally
Many distributors have data sets already established for their categories and a portion of these attributes are required. Being able to pull this data together quickly and efficiently will allow the time to market to move much more quickly. The faster your product gets on the distributors website the faster it generates sales. I previously worked at a big box distributor and the longest part of the onboarding cycle was gathering the product data and assets from the supplier. This was often because the data was owned and managed by a single resource, not in a centralized system or in disparate data silos making it difficult to grab the array of data from shipping dimensions and codes to product specifications to images and digital guides. If the product data and assets are managed in a centralized repository like a PIM or MDM, it makes it much easier, and not to mention more consistent, to provide that data to the distributors.
2. Provide complete data for every product
The more complete the data that you provide to your distributors, the more findable your product is going to be and the more confident the customer is going to be in your product amongst the similar products from competitors. Many distributors, like Amazon and Grainger, have a robust number of filters on their sites. If the data is left blank for your product, then it doesn’t show up when the filter is used.
For example, if you are manufacturing light bulbs and selling through a distributor but were to leave an attribute blank like “Color Temperature” or “Light Technology” when a customer selects a value for that attribute as a filter, your product does not populate as an option. It is now invisible to the shopping customer. Gathering the required data and making sure its complete is essential on the manufacturers end to make sure your product is as visible as possible.
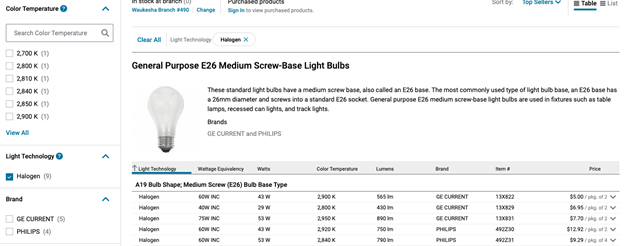
3. Include more and better images
The more complete your data set is, the more it will stand out from the competition. It is very likely that you aren’t the exclusive provider of your product segment to the distributor. A key way to differentiate yourself from the other products in the distributors category is to ensure you have all the key data needed for product comparisons. This includes images! In the items below, we see varying levels of product data and images. The item in the middle is the one least likely to be selected when compared with other products. The data is incomplete and it lacks any images. The customer is going to be far more confident in the purchase of an item that is more complete.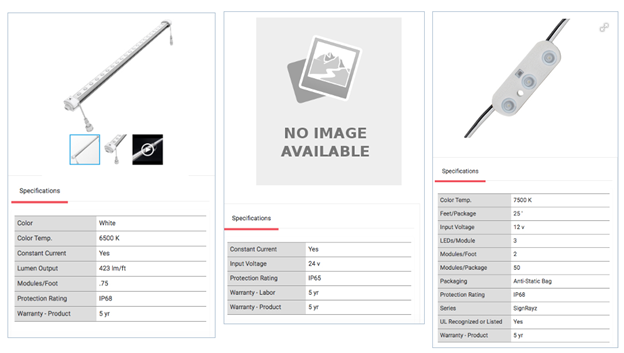
4. Provide extra product information on your own website
Even if you are selling through distribution you should still maintain information about your products on your own marketing site. When you have sites like Amazon selling many competing products from unknown or hard to find manufacturers, you find people are vetting items outside the distributor site. Sometimes the distributor site doesn't provide all of the information that you would like. So, these customers seek out manufacturers sites to do additional research about the products they are considering buying. This gives you a chance for you to tell your own product story and differentiate yourself through robust descriptions and product relationships.
***
If you are in the B2B space and want to ramp up your product data to meet these challenges and blow your competitors out of the water, reach out to us! We would love to help.
