This is a continuation of a previous post: What You Need to Know to End Information Chaos.
Business makes extensive use of taxonomy and metadata in a variety of scenarios including accounting, databases and inter/intra-net based applications to provide structure and organize information. All this is normal and straightforward. Chaos arises, however, when a business manager or executive asks questions that cut-across systems. When, for example, they want to be able to integrate engineering data, customer-oriented product information, customer information, and customer service complaints to identify new product-lines and solution opportunities.
To achieve the goal of visualizing a business problem by mining information repositories in a creative way to address complex issues involving multiple data repositories, taxonomies and metadata must be aligned to establish a comprehensive "single source of truth." The concept of a single source of truth is the mantra in the drive to put Master Data Management (MDM) into practice. However, the effort comes with certain practical and serious challenges. The most significant being the fact that different and well-governed information systems have different semantics and different metadata standards. Achieving semantic interoperability is a serious challenge, especially as business systems and network service architectures develop to meet organizational needs to adapt to a rapidly changing technology environment.
So what to do? How do organizations find ways to capture, manage, and derive understanding from a wide range of sources including its internal expertise resources and the stream of information provided by social media channels?
Start by taking snapshot of the organization's process and procedures. You’ll want to include people and system use cases, business rules, and metadata models. Look for two kinds of results:
- Clearly defined systems architecture with clear, accurate exchanges of data
- Wide-ranging, well-governed enterprise metadata standard and framework capable of capturing all types of business knowledge (such as: quantitative data, manageable asset information, product information, customer information, merchandizing information, and public sentiment).
Taxonomists must respect the pragmatic diversity of business vocabularies when building their metadata/taxonomy schemas. Business metadata labels content that has meaning for the business consumers and owners of that information.
The fact is organizations do have legitimate, divergent metadata needs. Combine this with a goal to capture sufficiently rich information that both allows extraction of known information needs while creating opportunities for new knowledge discovery you do have something of a paradox.
Taxonomy understands the "multiple perspectives" critique of the "single source of truth" view as asserting a need for disambiguation. The challenge presented by an organizations use of multiple definitions of "customers" does not imply metadata chaos or nor does it mean you cannot achieve standards based semantic interoperability. There is a solution.
To address the issue develop multidimensional conceptual frameworks expressed as faceted vocabulary maps managed by a governance process. The taxonomy development and governance process should:
- take a flexible approach to developing vocabulary to express nuance, and
- address issues of organizational complexity by asking experts and stakeholders to validate your decisions.
The diagram below illustrations a communication matrix that allows fact-finding and governance structures to work together to clarify the meaning of terms and to limit scope.
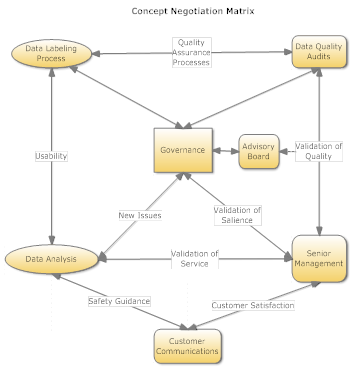
One problem you will encounter as you expand your vocabularies to fully disambiguate concepts is verbosity. Meanwhile, data systems are terse. Semantic clarity requires words to be clearly defined and limited to exactly one meaning. The use of multiple words to limit and clarify a concept is verbose. Best practices require tables to reduce data to canonical normal form, with clearly defined relationships and characteristics and to avoid verbosity. In organizations facing business merger and acquisition challenges, such an approach seems far from pragmatic and presents a risk to data quality and integrity.
The challenge organizations appear to face is the choice between not knowing what their data means (metadata chaos) and uncertainty about the meaning of the consistency and interpretation of their data and reports (data chaos). The apparent dilemma of choosing between metadata standards and data quality encourages information silos within centralized business organizations that require management to struggle with understanding its own business information, The consequence of information silos is that the task of tapping organizational knowledge become dependent upon people and subjective interpretation, and limiting the ability of the organization to both use to organizational knowledge resources and to leverage enterprise expertise domains (organizational chaos).
The fundamental take-away from this discussion is that metadata chaos can be avoided by a processes focusing on domain modeling, faceted structuring of semantic elements, and negotiation of language to eliminate ambiguities. Essential requirements of every metadata and taxonomy projects are the preservation of data integrity while achieving semantic fidelity. The belief that enterprises must to choose between chaotic metadata and chaotic data, and therefore need humans in order to disambiguate information is a high-risk strategy. The risks inherent in this strategy can be mitigated through a well implemented taxonomy engagement focused on establishing an interoperable semantic framework for an organization's entire knowledge domain.