Governance is a program used to ensure data is being managed efficiently. There are many aspects of governance that should be considered when designing your program. Some of these steps will be baked into the product information management (PIM) system, like user roles and assignments, and some won’t be, like a list of necessary processes. The level of governance in a PIM varies from system to system as well as how the PIM is set up. Governance is going to be different for every company, but there are some steps to take to make sure your data is optimized that apply to all.
- Establish a governance team
- Create a list of enterprise processes
- Develop a RACI (Responsible, Accountable, Consulted, Informed) chart
- Design process maps
Establish a team
Establishing a team is the first and most important step. The different players in product data need to be identified and user roles established. A governance council or taxonomist would be the owner of the product taxonomy and be the tie breaker for any major decisions relating to the taxonomy. They would ensure that the processes are in place and being followed. They would supervise taxonomy and data audits to ensure that the taxonomy is adhering to style guides and organization principles. Another role is that of data stewards. These are the folks that make the changes in the data in the PIM, fill the data and enact any change requests to the taxonomy. The product managers act as the subject matter experts that supply the data for products. Understanding who can edit, who can read only, who needs to be consulted etc. is all very important to the process and that is what the RACI and process map will identify.
Identify processes
The next step is to identify the processes needed to manage data. Some of these include new item onboarding, new category request, category change request, new attribute request and a taxonomy health check. There are many others, but let’s just dive in and look at one. A new category request may originate from a number of people in the governance team. The product manager may have a new type of product coming down the pipe that doesn’t fit in the current structure. The data steward may see that a particular set of attributes doesn’t apply to some items in a category and see the need to split that category in two. The governance council may see an organizing principle violation requiring the restructure of a portion of the taxonomy. Understanding the other processes that may intersect, such as item reclassification and attribute change requests, will be important while designing the governance program.
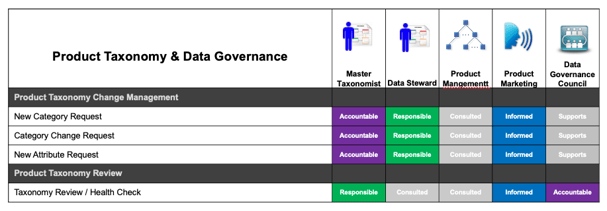
Develop a RACI chart
The RACI chart will help identify who has what role for each process. The roles are:
- Responsible: Who is responsible for doing the actual work in the process task.
- Accountable: Who is accountable for making sure the task is complete. This person can also be a tie breaker or decision maker.
- Consulted: Who needs to be consulted for information to complete the task.
- Informed: Who need to be made aware of major changes and updates. Laying this out will make it clear who has the right role for each process.
Here is an example of a RACI chart:
Create process maps
Last but not least is the creation of a process map for each process. This will lay out each task in the process, who need to complete those tasks and what system that task may be actioned in. It starts with a user story. “I am a product manager and have a new product line coming out that will require a new category in the taxonomy,” Then lay out the steps both in a written outline and a visual layout. An example is shown below.
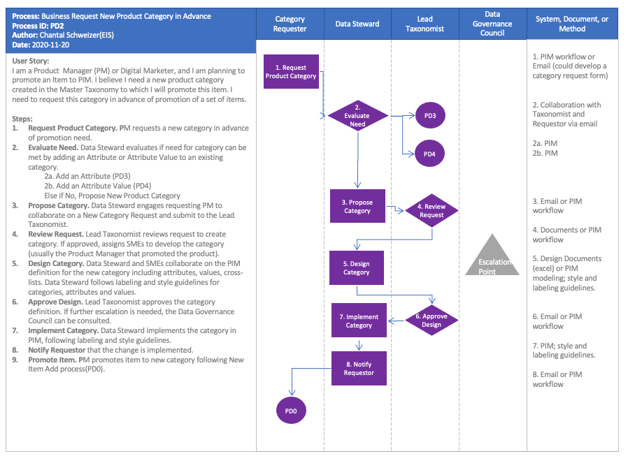
A process map should be created for all processes listed, and should include all those who are in the RACI chart.
So what?
So how does all this help optimize your PIM data for the long term? When you don’t have governance holding people accountable for the taxonomy and defining who can make changes in specific areas and functions, anyone could make changes at will. If everyone can make changes to the taxonomy, attributes, and data without following guidelines and organizational principles, the taxonomy can quickly become chaotic and hard to navigate. Duplicate categories would emerge if two product managers don’t agree on the attributes, which causes data inconsistency in the customers’ view of the information. Junk drawer categories would be created, such as “Other” because there isn’t a home for some secondary products and it’s easier to put it in a miscellaneous bucket rather than create a category for their specific sets of data.
A strong governance program will ensure that slips like this don’t happen. When a new category is added it will be evaluated and the correct attributes assigned so that when items are classified into it, the item will have the data needed by customers to make a purchase decision. Governance will make ensure that your data stays clean, consistent, and complete for the long haul.
If you need assistance in building a governance program, we can help! Please contact us if you want to develop your own program to ensure product data excellence.