Hybrid AI is a method of combining machine learning, which uses statistical models to analyze data, and symbolic AI, which is semantic-based and provides insights into meaning. By using the strengths of each technique, an outcome can be achieved that is more powerful than would be achievable by either one alone.
What is an example of Hybrid AI in action?
Let’s start with an example. Imagine that a machine learning system is trained to identify defective products. It is shown hundreds or thousands of examples of defective and non-defective products. It can then accurately distinguish between good products and defective ones. This is one of many use cases where machine learning is effective, and may well be both faster and superior to human performance, after the system is trained. But once the defective product is identified, what next?
At that point, more information is required to make this identification process useful. What product line did it come from? What was the cost of losing that piece? What vendors or suppliers were involved? Who owns the process where the defect was found? What content needs to be provided to inform managers about the issue? The machine learning data needs to be contextualized so you can act on it. That requires symbolic AI, which represents knowledge and provides semantic understanding and reasoning, including development of rules for extracting relevant knowledge.
The ultimate goal is to allow computers to simulate, as closely as possible, the functioning of the human brain. Computers don't think like us--the human brain is vastly more complex, versatile, and adaptable than any machine. The brain has 40 different neurotransmitters. One neuron can connect to ten thousand others. There's a level of complexity that's unimaginable and cannot yet be matched by a computer. But hybrid AI provides the scalability of machine learning with the nuances of symbolic AI to allow us to simulate the brain’s performance more closely, and provide information the system can act upon.
How are Knowledge Graphs and Information Architecture Related to Hybrid AI?
One way to represent knowledge is through a knowledge graph that shows connections and other relationships among different data elements. The knowledge graph gives us a reference point, so that we can understand what is in the data, especially unstructured data, and derive meaningful insights. Information architecture in the form of a knowledge graph is the foundation for symbolic AI.
Both machine learning and symbolic AI perform better when information is structured and metadata is available. Tagged data is required for training machine learning (supervised learning). Symbolic AI requires rules about language, and data that is structured. Therefore, hybrid AI as a whole will be more successful when a solid, well thought out information architecture has been developed as a foundation.
Information architecture always starts with identification of a business problem and the priority use cases. In addition, you need to understand who it impacts and how it impacts the organization. Develop baseline metrics so you know what success looks like as the implementation of the information architecture evolves. Then find out what content, data, and information the users need, and generate organizing principles around it. In order to automate a process, you need to understand it.
How Does Information Architecture Improve Data Discovery?
Data discovery is the process of analyzing large quantities of content, including research documents, news stories, press releases, and emails for the purpose of understanding the business environment, seeking new opportunities and reducing risk. Data discovery should be accompanied by a strategic plan that provides for the effective use of the information. Intelligent analytics reveals the relationships among organizations, key influencers, topics, events, and other entities.
Taxonomies are the building blocks for data discovery, and most organizations need multiple taxonomies that represent different aspects of an organization. These may include products, services, processes, solutions, customers, interests, and types of content. Each item in a category has different attributes; for products, they may include description, price, brand, and so forth. Customers have attributes such as geographic location, purchase history, and age.
Using Ontologies
Defining the relationships among the different taxonomies produces an ontology. For example, there may be content relating to different products, or areas of interest for different customers. These relationships allow a company to do things like personalization. An ontology consists of multiple taxonomies and all the relationships between them.
Taxonomies vary greatly among industries. In the life sciences, a set of taxonomies would include drugs, both branded and generic, diseases that the drugs would treat, and mechanisms of action. For insurance, the taxonomies might cover products, services, and risks. And for an industrial distributor, they might be products, industries, and interests. The domain of knowledge is represented by collection of ontologies.
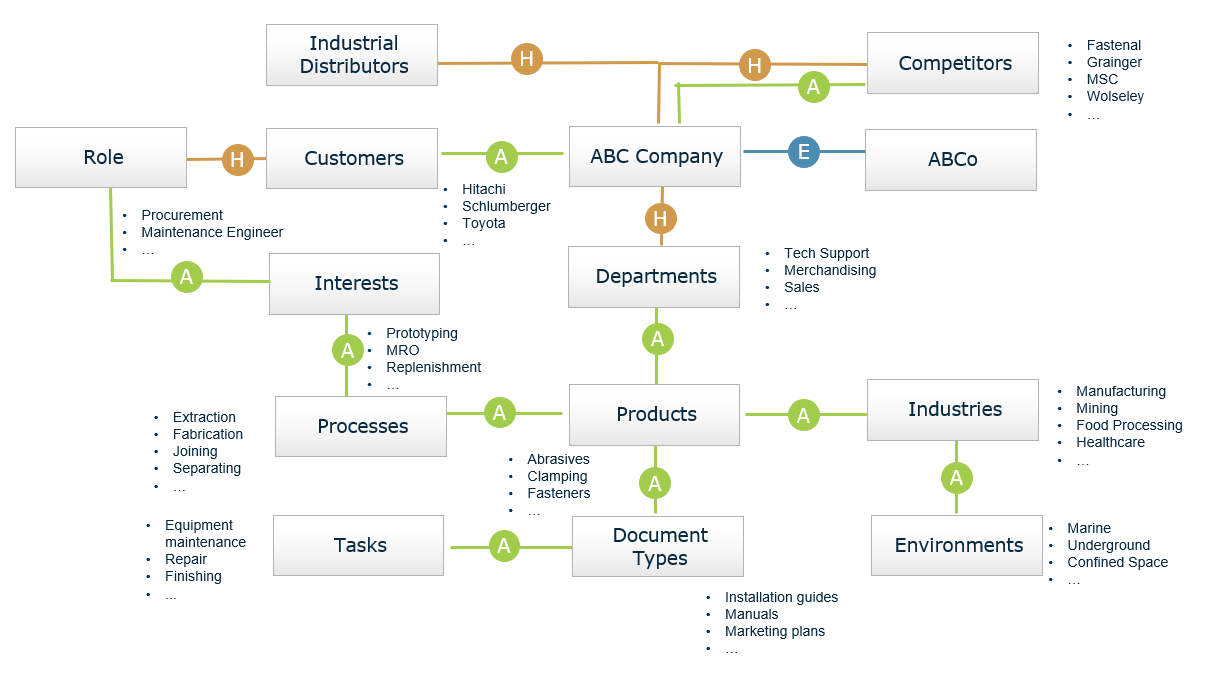
An ontology for the industrial distribution company is shown below.It shows the hierarchical relationships in taxonomies but also shows the associative relationships that reflect what products are appropriate for certain industries. They show the conceptual relationships among the different elements.
Industrial Distribution Ontology Example
Using Knowledge Graphs
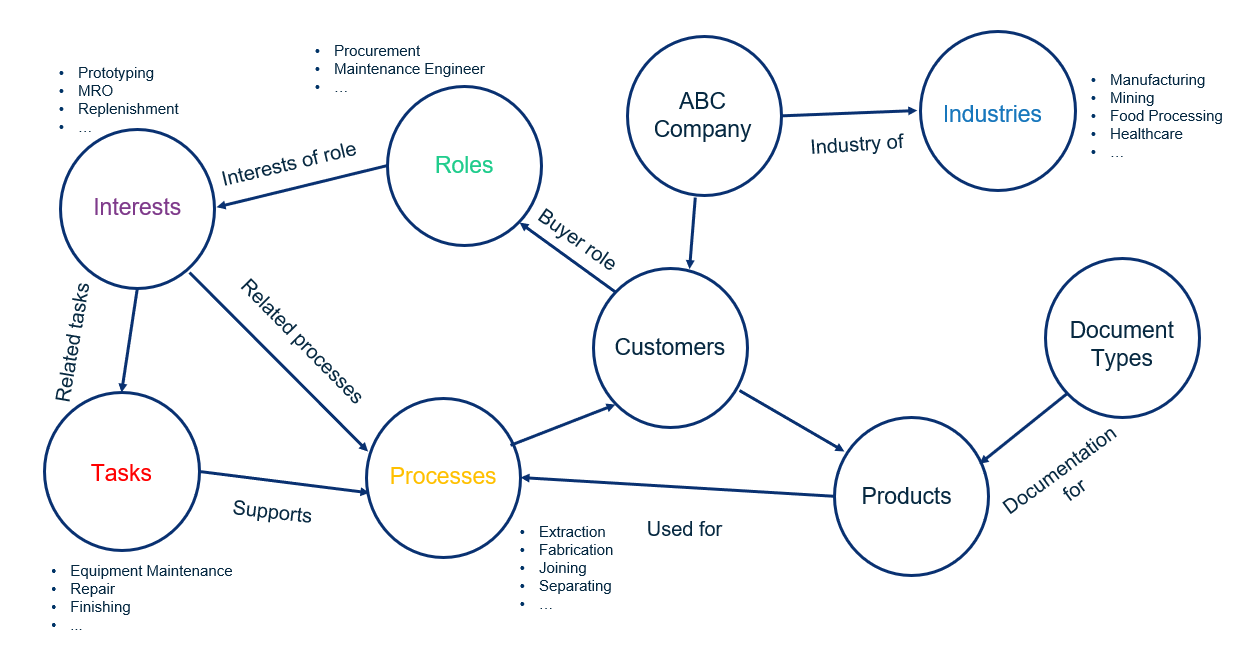
A knowledge graph can be derived from a combination of a taxonomy plus ontology plus data. First, describe the entities in the domain through a taxonomy. Then show the relationships among taxonomies to develop an ontology. Finally, add data to the ontology to form a knowledge graph that reflects the connections. The knowledge graph provides multiple ways of navigating through data, whether it is structured or unstructured. (See figure below.)
Industrial Distribution Knowledge Graph Example
 Every critical business process revolves around language, but language is notoriously difficult for computers to understand and respond to. A typical example is the headline, “Banks closed due to flooding.” At first, it might seem that bad weather caused a financial institution to close. But in the news story, it was the river banks that were closed, not a financial institution.
Every critical business process revolves around language, but language is notoriously difficult for computers to understand and respond to. A typical example is the headline, “Banks closed due to flooding.” At first, it might seem that bad weather caused a financial institution to close. But in the news story, it was the river banks that were closed, not a financial institution.
Ambiguity of language is one of the most problematic issues in analysis of unstructured data. It has required significant intervention by humans, which makes language-driven processes difficult to scale. A particular problem is understanding intent, which if not done properly, is a major obstacle to fulfilling customer requests. It is in these situations that hybrid AI can be very beneficial.
The extraction of entities from text allows for detection of fraud, identification of risk, and other vital information that supports decision making. However, the system must have the vocabulary to make this work—it does not work without understanding context.
Real World Applications
One of the real world applications for hybrid AI is in financial data discovery. The goal is to automate the extraction of information about financial assets, to bring efficiency to back office processes and scale data creation. The financial environment has a large number of documents and events such as mergers and acquisitions, bankruptcies.
The financial world, whether asset management companies or those who provide information to financial organization, must contend with a flood of documents—articles, reports, and other digital assets. Data associates are dealing with a high number of company events. Companies are merging, being acquired, filing for bankruptcy, and they're also dealing with financial assets.
Monitoring these events is very costly, often manual-intensive, and is limited by team capacities. So how do these organizations contend with this volume of information to decide, for example, whether they should invest in developing a certain consumer financial product?
In one case study, the consultant collected content from various services and ran it through a process for data extraction. A natural language platform automated the extraction of key parameters. A user interface was designed so that subject matter experts could navigate within documents, review information, and evaluate it in a collaborative authoring environment. The user interface provided for seamless evaluation of key parameters and database ingestion. Training sets were prepared for data modeling. These models were knowledge models, because they combined machine learning techniques with a knowledge base from a subject matter expert.
Summary
Comparing machine learning and symbolic AI shows how complementary the two approaches are. By its nature, machine learning requires a lot of data but less subject matter expertise on the part of the user, and is a good match where data is abundant and tasks are straightforward. Symbolic AI requires less data and has lower computational requirements and therefore lower computational costs. However, it requires human expertise, and the curation of domain-specific expertise can be complex, time consuming, and expensive. Hybrid AI is a win-win situation, combining the best of both.