Enterprise technology conferences increasingly feature apocalyptic messaging around artificial intelligence adoption. Vendor presentations warn of existential business threats for organizations moving too slowly. Marketing materials suggest competitors will obliterate laggards. Executive teams receive urgent calls to deploy AI immediately or face obsolescence. This rhetoric produces more anxiety than actionable strategy.
A recent vendor webinar exemplified this trend. The presenter displayed a slide positioning AI adoption as a survival imperative—essentially declaring that businesses without artificial intelligence face imminent failure. Another speaker emphasized speed as critical, insisting organizations must move aggressively into full-scale AI deployment now or perish. While these pronouncements generate dramatic presentations, they provide little practical guidance for technology leaders actually responsible for implementation.
The proclamation to embrace AI urgently or die raises obvious questions: What specific actions should organizations take? Which business processes require AI intervention first? How do teams prioritize among competing initiatives? The alarmist framing offers no answers. It simply demands immediate, comprehensive action without acknowledging the substantial foundational work successful AI deployment requires. This gap between urgency rhetoric and operational reality explains phenomena like organizations offering seven-figure salaries for AI specialists while lacking basic data management capabilities necessary for those specialists to succeed.
The actual challenge facing enterprises has little to do with artificial intelligence technologies themselves. The barrier to value creation lies in information assets—specifically their quality, accessibility, and structural organization. Organizations cannot solve data problems by hiring expensive AI talent or licensing sophisticated models. They must address information architecture systematically before advanced algorithms can deliver meaningful business outcomes.
The Data Quality Gap in Executive Perception
Recent research by Tom Davenport and Priyanka Tiwari reveals troubling patterns in how leadership teams assess their data readiness. Their Harvard Business Review study found that 46% of executives acknowledge data quality issues within their organizations. This statistic likely understates the problem significantly. The remaining 54% either lack visibility into their data challenges or resist confronting uncomfortable truths about information management failures.
Consider the broader survey findings. Over 90% of executives recognize data strategy importance for AI initiatives. Yet more than half have implemented no changes to their data management practices. Only 11% express strong confidence in their data foundations for generative AI applications. These numbers reveal profound disconnects between stated priorities and operational realities.
Organizations proceed with AI implementations despite knowing their information assets cannot support them. Executive teams understand abstractly that data matters, yet fail to invest in the unglamorous work of improving data completeness, consistency, and structure. Technology vendors eager to close deals rarely emphasize these prerequisites. The result: expensive AI projects launching atop information foundations guaranteed to undermine their effectiveness.
This pattern repeats across industries. Financial services firms deploy customer experience AI without unified customer data models. Healthcare organizations implement clinical decision support while maintaining fragmented, inconsistent medical records. Manufacturers pursue predictive maintenance solutions despite lacking standardized equipment taxonomies. Each case involves sophisticated AI technologies attempting to extract value from inadequate information architecture.
The disconnect stems partly from technology vendor messaging emphasizing model sophistication over data fundamentals. Demonstrations showcase impressive capabilities using carefully curated test datasets. Real-world deployments encounter messier realities: incomplete records, inconsistent terminology, missing metadata, conflicting data sources. These information quality issues constrain AI effectiveness far more than model architecture choices.
Context as the Core Personalization Challenge
Artificial intelligence applications fundamentally aim to deliver appropriate information to specific individuals in particular situations. This objective—getting the right knowledge to the right person at the right moment—has driven knowledge management and personalization efforts for decades. AI simply provides more sophisticated mechanisms for achieving this longstanding goal.
Effective personalization requires understanding both users and content in multi-dimensional detail. User understanding encompasses demographic attributes, behavioral patterns, stated preferences, inferred interests, historical interactions, and contextual signals indicating current needs. Content understanding includes topical focus, complexity level, format type, recency, authoritativeness, and relationships to other information assets.
Digital interactions generate continuous streams of behavioral data revealing user contexts: search queries indicating information needs, clickstream patterns showing navigation preferences, campaign responses demonstrating content resonance, support interactions exposing pain points. These signals enable sophisticated personalization—but only when systems can interpret them meaningfully and connect them to appropriately characterized content.
Here lies the data quality challenge. Behavioral signals mean nothing without structured frameworks interpreting them. A user searching for "high-performance industrial pumps" generates a clear signal—but systems require taxonomies categorizing pump types, ontologies relating pumps to applications, and metadata tagging content by equipment specifications. Without this semantic infrastructure, even the clearest user signals cannot guide appropriate content delivery.
Generative AI and Retrieval Augmented Generation promise to improve personalization by making information access more conversational and context-aware. However, RAG systems depend entirely on retrieval effectiveness. When underlying content lacks proper structure and descriptive metadata, retrieval fails regardless of how sophisticated the generation component performs. The persistent search and retrieval problem simply manifests in new AI-powered forms.
Retrieval Effectiveness as the Persistent Bottleneck
Search technology evolution over decades—from keyword matching through semantic analysis to vector similarity—has not eliminated the fundamental dependency on content quality and information structure. Advanced algorithms cannot compensate for poorly organized knowledge repositories. This constraint applies equally to traditional search engines and modern RAG-based AI systems.
Effective retrieval requires two prerequisites. First, relevant information must exist to answer queries. Second, that information must be structured and tagged to enable discovery. The latter condition consistently proves more problematic than the former. Organizations typically possess the knowledge needed to address user questions—it exists somewhere in technical documentation, support guides, policy manuals, or expert communications. The challenge lies in making that knowledge findable.
Consider the common request to make enterprise search work like Google. What does this actually mean? Users want the ability to search vast information collections and quickly receive relevant results. The comparison misses a critical point: Google search effectiveness results from massive investments in content optimization, link analysis, and ranking algorithms specifically designed for public web content. Organizations wanting similar effectiveness for enterprise search must make comparable investments in content structure, metadata enrichment, and relevance tuning for their specific information environments.
Leadership teams typically resist this reality. They want immediate search effectiveness without the effort Google and other successful search providers invest in information architecture. This resistance explains persistent search disappointment across enterprises despite decades of technology advancement. The problem isn't search algorithms—it's information organization.
AI-powered search and RAG systems face identical constraints. Vector embeddings and semantic similarity matching represent powerful retrieval techniques. However, they cannot locate information that lacks adequate metadata signals. A support document containing the exact solution to a technical problem remains undiscoverable if not properly tagged with equipment model, failure mode, and solution type metadata. Advanced AI simply fails faster than traditional keyword search when confronted with inadequate information architecture.
Leveraging AI for Information Architecture Enhancement
Fortunately, the same AI technologies requiring quality information can help improve it. Language models excel at extracting structured information from unstructured text, standardizing terminology, filling metadata gaps, and identifying relationships between content elements. Organizations can employ AI strategically to address the very data quality issues that constrain AI application effectiveness.
The approach centers on content preprocessing before embedding into vector spaces for retrieval. Naive implementations chunk documents arbitrarily without semantic consideration. Text gets divided by character count or paragraph boundaries regardless of meaning. These arbitrary chunks often split coherent concepts or combine unrelated information, degrading retrieval effectiveness.
Semantic preprocessing treats content more intelligently. Documents get analyzed to identify logical units: complete answers to specific questions, discrete procedural steps, coherent concept explanations. These meaningful chunks then receive descriptive metadata before embedding: question types they answer, procedures they describe, concepts they explain, contexts where they apply. The metadata provides crucial signals enhancing vector similarity matching.
Effective semantic preprocessing requires two information architecture components. First, content models defining metadata structures for different information types. A troubleshooting guide requires different descriptive fields than a product specification or policy document. Content models specify these type-specific metadata requirements systematically.
Second, controlled vocabularies and ontologies provide standardized terminology for metadata values. Rather than allowing free-text tags, content models reference enterprise taxonomies: product categories, customer segments, business processes, technical domains. These controlled vocabularies ensure consistency and enable faceted filtering complementing vector similarity search.
Together, content models and ontologies form a reference information architecture—the organizing principles and standardized terminology governing how organizations structure and describe their knowledge assets. This architecture serves multiple purposes: guiding content creation, enabling consistent tagging, supporting search and retrieval, and providing context for AI-powered applications.
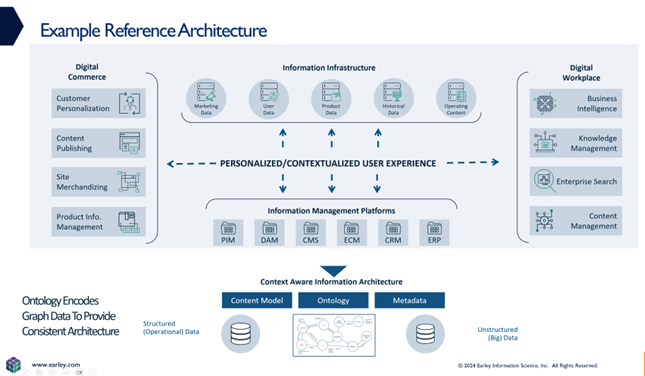
Enterprise Ontology as Foundational Knowledge Framework
An enterprise ontology represents the comprehensive conceptual model of organizational knowledge. It encompasses multiple domain-specific taxonomies and the relationships connecting them. Think of it as the intellectual scaffolding supporting information management across all business functions and technology systems.
Consider the taxonomies required for a customer relationship management system: customer types categorizing different market segments, content types classifying marketing materials, product categories organizing offerings, campaign types distinguishing promotional approaches, industry classifications for B2B contexts. Each taxonomy provides standardized terminology for describing different aspects of customer engagement.
An ecommerce platform requires similar but distinct vocabularies: product hierarchies organizing catalog structure, attribute schemas describing product characteristics, fulfillment options specifying delivery methods, return reason codes categorizing customer issues. These taxonomies must align with related systems—product information management, inventory management, customer service knowledge bases—to ensure consistent terminology across customer touchpoints.
Internal employee-facing tools demand the same semantic consistency. Support representatives need access to product information matching what customers see online. Technical documentation must reference the same equipment models used in inventory systems. Training materials should employ terminology consistent with policy documentation. When different systems use divergent vocabularies for the same concepts, employees waste time translating between inconsistent terminologies rather than serving customers effectively.
The ontology connects these disparate taxonomies through explicit relationships. Products relate to services through "services for product" relationships. Customers connect to industries through "customer in industry" associations. Content links to products via "content about product" references. These relationships enable sophisticated queries traversing conceptual connections: "Find technical documentation for products used in healthcare industry experiencing specified failure modes."
Without ontological structure, organizations maintain isolated taxonomies managed independently by different departments. Product teams develop their categorization schemes. Marketing creates distinct content type classifications. Customer service establishes separate issue taxonomies. Each system optimization produces local improvements while enterprise-wide information fragmentation persists. The ontology provides the unifying framework aligning these disparate efforts toward coherent enterprise information architecture.
Implementing AI-Powered Data Enrichment
Reference architectures combining content models and ontologies enable systematic data quality improvement using AI. The approach ingests poorly structured data alongside architectural frameworks specifying how information should be organized. Language models then transform incomplete, inconsistent records into standardized, enriched versions conforming to content model specifications and employing controlled vocabulary terms.
Multiple information sources contribute signals guiding this transformation. Reference taxonomies provide standardized terminology. Related documents offer contextual clues through co-occurrence patterns. Industry standards suggest expected attribute values. Historical corrections demonstrate common transformation patterns. User behavior data reveals which attributes users actually query. Each signal type contributes to the AI's understanding of how to structure and enrich information correctly.
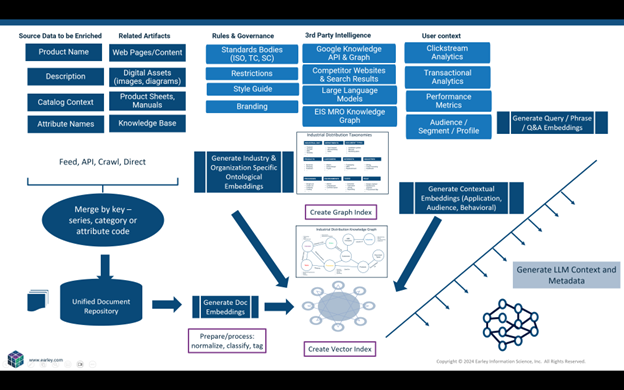
Prompt engineering orchestrates these inputs systematically. Rather than simply asking models to "improve this data," structured prompts specify desired transformations precisely: extract product attributes conforming to this schema, standardize category assignments using this taxonomy, fill missing fields based on these related records, validate completeness against this content model. Templated prompts with variable substitution enable applying consistent transformation logic across thousands or millions of records.
Consider product information management as concrete example. Raw product data often contains manufacturer part numbers, terse technical codes, and sparse descriptions meaningful only to engineers. Customers cannot search effectively using this information. An AI-powered enrichment process transforms these records by extracting standardized attributes, mapping cryptic codes to plain-language categories, expanding descriptions with customer-relevant details, and adding metadata enabling faceted search.
The before-and-after comparison proves striking. Original records contain minimal usable information: opaque product codes, single-line descriptions, missing categorization. Enriched versions provide comprehensive details: plain-language product names, multi-paragraph descriptions highlighting key features, structured attribute sets enabling comparison, proper taxonomic classification supporting navigation. Users can actually find and evaluate products meaningfully.

This same methodology applies to other information types. Customer records get enriched with standardized industry classifications, segmentation attributes, and relationship mappings. Support content receives proper categorization, equipment model tags, and problem-solution metadata. Policy documents gain audience tags, topic classifications, and effective date tracking. Each enrichment project follows the pattern: define target structure via content models, provide reference vocabularies through ontologies, employ AI to transform existing information assets.
Moving from Urgency Rhetoric to Strategic Action
Yes, artificial intelligence represents a critical enterprise capability. Yes, organizations must integrate AI into core business processes. Yes, properly implemented AI improves customer and employee experiences substantially. However, apocalyptic warnings about competitive extinction serve no productive purpose. They create panic without providing actionable roadmaps.
Effective AI strategy begins with honest assessment of information architecture readiness. Organizations must audit their data quality, content structure, and semantic frameworks before pursuing aggressive AI deployment. This assessment reveals gaps requiring remediation: missing metadata schemas, inconsistent terminology, inadequate content models, absent governance processes.
Armed with realistic understanding of current state, leadership teams can develop phased approaches addressing foundational requirements systematically. Initial phases focus on establishing reference architectures, implementing controlled vocabularies, enriching high-priority content, and demonstrating value through targeted AI applications. Subsequent phases expand coverage to additional domains, deepen ontological relationships, and scale AI applications to broader use cases.
This measured approach lacks the dramatic urgency of "AI or die" rhetoric. However, it produces sustainable capabilities rather than expensive failures. Organizations investing in information architecture create reusable assets supporting multiple AI applications over time. Those chasing urgent AI deployment without addressing data foundations build on sand, experiencing disappointing results that erode confidence in AI value.
The path forward emphasizes data quality and structural coherence as prerequisites, not afterthoughts. Improve information organization first, then deploy AI applications leveraging that improved foundation. Use AI itself as a tool for accelerating data quality improvement, creating virtuous cycles where better data enables more effective AI which further enhances data quality. Focus investments on information architecture rather than desperate talent acquisition or vendor technology that cannot compensate for inadequate data.
Ignore the fearmongering. Take deliberate action on data quality and information structure. Build the foundations that enable AI to deliver genuine business value rather than expensive disappointment.
This article was originally published on CustomerThink and has been revised for Earley.com.