EIS was recently engaged by a client who needed an enterprise approach for addressing search and information access challenges. Like many large enterprises, this client had a centralized service to provide and manage technology for business units and the business units were responsible for their data and content. This is how it should be. However, the organization’s business units were not able to locate the content, digital assets, and knowledge that was needed to serve their customers. The IT department, which was doing its job of providing the infrastructure, was being blamed for this problem.
Don’t blame the technology
In digging more deeply and assessing the root cause of the inability of users to find what they needed, it became clear that the search technology was not the fundamental problem. The search function was actually working. The real issue was that few standards and processes were in place for to curating, tagging, managing and organizing the organization’s content. Although there was room for improvement, the technology was working and was reasonably advanced. But the content had not been processed in a way that allowed for effective search. The path to a solution began with a maturity assessment across six dimensions of capabilities that need to be in place to improve search, information retrieval and knowledge reuse.
How should the IT organization respond? Well, imagine the following scenario – IT, as a central service, installed an ERP system, for example, SAP. But the business owners did not like to put data into the system. Sometimes they did and sometimes they didn’t. When invoices came in, the accounts payable staff pushed back, saying “All those numbers… you have to put them into the system. Then they need to tie together and add up. It’s just too inconvenient for me.” Sometimes they entered all of the information, and sometimes they didn’t. Sometimes they added all of the account details, other times left things out.
When the accounting staff didn’t know where to post an entry, they would create a new account – this way they had their own personal area in the chart of accounts that they could use more easily because the general ledger wasn’t intuitive enough. Each time a new manager came in, they also changed the chart of accounts to something they preferred, or they decided to just start over.
Of course, this is preposterous. The business would not run very long this way. Or people who operated in this manner would quickly be out of a job. If the business used ERP technology in this way, it could not blame IT for the fact that the books weren’t balancing and payables were overdue causing vendors to stop providing needed products and services. Yet this philosophy is often applied to unstructured content, with the expectation that little adverse impact will be felt.
Impact slowly accumulates throughout the organization
While one could argue that the unstructured content that people have trouble locating isn’t mission critical – or isn’t to the same degree that accounting systems are -- it actually is mission critical. The difference is that the impact of not being able to find information has a different clock speed and is therefore not immediately noticed. In fact, the impact can evolve so slowly and accumulate over time so that leadership does not even recognize that there is a problem.
Instead, the organization gradually adapts with workarounds and added staff and “acts of heroics”. Or new technology is deployed that at first appears to improve things but in fact contributes to the problem and even makes it worse, because it deflects the need for foundational change. The solution to application proliferation cannot be another application unless it replaces multiple systems. But more often than not, the old applications are kept around for historical reasons (since migration is too costly in many cases) and over time the new system becomes messy and clogged with irrelevant and redundant information and haphazard taxonomies and organizing structures.
Collaboration and digital technology for unstructured information has not been around as long as the tools used to manage transactions and structured information. In the days of paper, there was something called the file room where important documents and corporate records were created and filed away. It was attended to by curators, and documents were signed in and out using a formal process. People still had local working files, but important content was retrievable due to the attention and resources spent on the process by these record managers.
With today’s digital transformation programs in flight, unstructured content is beginning to take center stage. Digital transformation is (supposed to be) about an end-to-end value chain to serve the customer and streamline internal operations while doing so. Successful digital transformations require data transformations. The value chain is a flow of information to and from the customer, with the end result being that their needs are met quickly and efficiently.
The seemingly inconsequential accumulates
Many organizations are spending enormous sums on customer-facing capabilities. Yet they find that there is so much friction in supporting their business processes that they are unable to realize the value of their investment and provide the necessary high-quality customer experience. Friction in supporting processes may seem inconsequential, but it can become significant as they accumulate through the value chain. Not being able to locate the information that is needed, forcing re-creation of that information, or using out of data information are obvious sources of friction.
This problem may be addressed with additional staff to handle workloads that are inefficient. However, that addresses only one aspect of the problem. The lack of integration across systems slows things down. The impact is felt throughout the organization. Decisions take longer because executives must wait for information. New products are slower to market because R&D does not have immediate access to resources. Customer service is less responsive. In general, problems take longer to solve and the organization has less agility in a fast-moving marketplace.
As competitors improve their ability to streamline information access and can serve customers with fewer resources, faster and can adapt to their needs more quickly and efficiently, the end result will be loss of market share and lower profits.
The impact of these inefficiencies is buffered somewhat by the fact that the organization’s competitors are likely saddled with the same issues. But those who solve them more quickly and effectively will have a definite edge.
Another factor is the changing nature of the workforce. Executives are getting more technologically savvy and realize that younger employees have higher expectations about the tools they work with. These younger workers are less willing to tolerate cumbersome technologies than
were previous generations—which did not grow up with easy-to-use consumer applications—and expect to have the tools they need to do their jobs.
Organizations are becoming aware of the potential of AI and many want to understand how to use it. The biggest obstacle to success with AI is the “lack of appropriate training data” (See the IT Pro article: “The Problem with AI”). If the foundational work is not put into place to properly structure, organize and curate data and content, the organization will be severely constrained in its ability to operationalize AI driven solutions to improve operations and provide the experience that customers expect and demand.
Content and data fuel AI
Artificial intelligence runs on data. Machine learning algorithms have been used to deal with unstructured content for at least the past 20 years. Search engines use machine learning to cluster and organize documents and content, with mixed results. Even those that could get the job done were not easy to use. But now, with cognitive technologies, market expectations are such that computers will be easier to deal with and be able to provide information quickly and efficiently using natural language – either through speech or chat.
The reality is, however, that AI tools have to be “trained” before they can perform their tasks properly. The training requires data and content that is appropriate to the domain in which the AI is operating. A support bot needs support content, for example. A commerce bot needs product data. In the parlance of Amazon’s Alexa, this training content and resulting capabilities are called “skills.” In fact, these so-called skills are no more than a response triggered by the user’s utterance or request (properly interpreted of course), which accesses sources of unstructured content and return the content as a spoken or written response.
The role of knowledge engineering
While conceptually simple and straightforward, the details of structuring content for AI correctly is enormously challenging. The content that feeds these bots needs to be architected and engineered in a way that allows retrieval based on nuanced signals from the user. If the task is very narrowly defined, the content structure does not have to be as complex. But organizations are also using chatbots to access large repositories and therefore the content models that organize documents in repositories require multiple dimensions to their structure. (See diagram - semantic processing and faceted retrieval). This organization and curation will also serve the needs of employees. The content that is needed to train AI is the same content that employees need to perform their jobs.
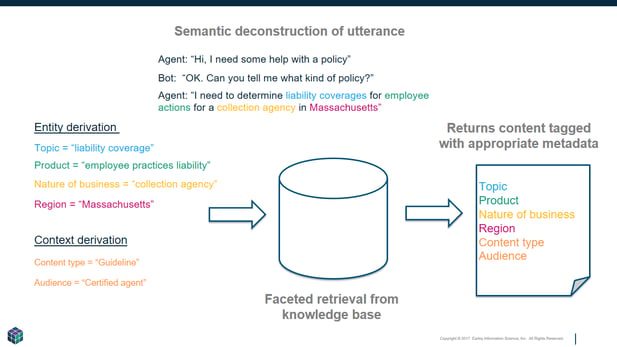
Figure 1: Semantic processing and faceted retrieval requires construction of a knowledge architecture.
This approach to content is not necessarily new, but it is advanced compared with the way most organizations deal with unstructured content today. The newest element is the need to better interpret the user’s intent. People use ambiguous terms and expect precise results. It is easier to ask for clarification in the form of a dialog than it is to get people to click through multiple facets and navigational nodes in a knowledge base. In fact, the bot is giving the user hints about what the structure of the knowledge base is and what is needed to get the precise result they are looking for. People want an answer rather than a list of documents. The content has to be aligned with the intent and needs of the user.
Since many organizations do not do a good job building enterprise taxonomies, the organizing approaches, taxonomies and metadata currently in place need to be revamped to ensure that the bot is capable of returning the correct information. A workflow also needs to be developed to manage the content lifecycle and keep it up to date.
The bot can prompt the user for each detail in the form of term lists in the facet, or entities can be extracted from the user’s request through semantic analysis. In either case, the knowledge architecture, which includes taxonomies and metadata, needs to be designed in a sophisticated and nuanced way in order for the correct content to be retrieved.
The broader value to the organization is that this architecture is what is needed to solve the problematic issues with the unstructured content in the first place. Knowledge engineering and content processes to feed chatbots should not be a separate effort, but should be recognized as part of an overall information strategy. Because the technology is new, and a focus on AI is required in order to develop applications such as chatbots, enterprises are setting these groups up to specifically build AI content. Over time, however, they should be integrated into the function that manages content rather than fragmenting that content in separate applications and repositories.
The same ontology should be applied to content whether specifically designed for a bot or for customer and employee self service, for example. Metrics and governance processes have to be part of the program as it evolves. This approach will keep content and knowledge architecture aligned with the needs of users, whether they are within the company or external customers and partners.
Contrary to what many organizations assume when they cannot locate their information, technology is not usually the problem. Having an information architecture that is designed for careful curation of unstructured content not only facilitates an organization’s current tasks, such as finding mission-critical content, but paves the way for a quantum leap as it begins to develop AI-based solutions that will at first provide a significant competitive edge but soon after will become required table stakes. Not building this today will introduce competitive threats tomorrow.
Need help with your own transformation program? Lay the foundation for your organization’s success with our Digital Transformation Roadmap. With this whitepaper, assess and identify the gaps within your company, then define the actions and resources you need to fill those gaps.