Knowledge graphs capture substantial market attention currently, though underlying principles span decades rather than representing novel innovation. Technology trends frequently rebrand established concepts creating perception of novelty while building on longstanding foundations. Organizations increasingly recognize knowledge graph potential yet struggle identifying practical next steps building business capabilities leveraging this technology approach.
Historical analysis reveals knowledge and data representation development from 1950s through present day. Industry researchers trace how building blocks and core principles evolved over decades. The challenge of making unstructured information meaningful while linking it to structured data has consistently centered AI initiatives throughout this period. Contemporary enthusiasm reflects maturation and accessibility rather than fundamental invention.
Persistent Information Management Challenges
Every organization confronts diverse data challenges. Structured data encompasses accounting systems, transaction records, operational metrics, process tracking, external feeds, digital experience streams, workplace technology outputs, customer behavioral patterns, manufacturing efficiency data, and ecommerce interactions. Integrating multiple structured datasets into coherent pictures poses ongoing technical challenges.
However, unstructured content management proves even more difficult and costly. Unstructured materials span documents, images, and explicit knowledge: policies, procedures, manuals, troubleshooting guides, installation instructions, product designs, engineering diagrams, blueprints, and additional codified expertise. Content management challenges persist defying permanent solutions as new content types emerge, information flows accelerate, technologies evolve, and marketplace dynamics shift continuously.
Enterprises transitioned from formal centralized document control through records management functions toward completely decentralized creation and management. This shift challenged records managers as anything potentially became official records—a reality anyone involved in litigation holds understands. Growing regulatory complexity makes transaction records, business process documentation, and relationship records increasingly critical for compliance, elevating management importance.
The fundamental "how do I find what I need" problem has intensified over years. Vendors promoting search, content, and knowledge management solutions position latest technical approaches as complete answers. Organizations adopt new tools expecting lasting improvements. Initial deployments succeed—users locate information effectively briefly.
Unfortunately, rushed implementations typically neglect information scaffolding—organizational structures supporting content. Inevitably, systems fill with additional content lacking consistent attributes, file naming conventions, or controlled tagging. Library science principles get violated systematically. As disorder becomes untenable, beloved systems transform into targets of user frustration. Users complain about tools they previously praised. However, technology isn't the problem—implementation approaches lacking forethought about user needs and usage contexts create failures.
Business and technology leaders conclude new tools will solve problems. They adopt replacements demonstrated impressively, discussed in articles, or recommended by colleagues. Cycles repeat without addressing fundamental causes.
AI Addressing Information Architecture Gaps
Cognitive AI emulating human thought and responses reduces human cognitive loads through natural language search, virtual assistants, and personalized experiences with helper bots and chatbots. Some AI technologies attempt compensating for organizations' historical poor design and information hygiene. Knowledge graphs represent enterprise information scaffolding informing algorithms about importance hierarchies while addressing unstructured text tagging deficiencies.
Knowledge graphs admit multiple definitional perspectives. Digital leaders recognize information must organize helping customers locate needed items—products or problem-solving information. Taxonomies organize information through parent-child or whole-part structures. Ecommerce product catalogs exemplify this: power tools contain power drills containing cordless drills. Product pages enable filtering by brand, price, size, voltage, battery type through taxonomy-defined lists and controlled vocabularies.

Multiple taxonomies create comprehensive digital experiences. Relationships build between taxonomies. When product taxonomies relate to service taxonomies, specific service availability for products becomes explicit. Industrial distributors employ multiple taxonomies describing beyond products—encompassing comprehensive information domains.

Defined inter-taxonomy relationships constitute ontologies. Ontologies contain three relationship types: hierarchical parent-child whole-part structures defining category membership, equivalence relationships capturing non-preferred terms like synonyms and acronyms, and associative conceptual relationships connecting related concepts. Creating ontologies involves mapping these relationship patterns.
Industrial examples reveal additional possibilities. Customer industry understanding prioritizes certain categories. Buyer roles and interests further inform product recommendations addressing particular processes, environments, tasks, and objectives.
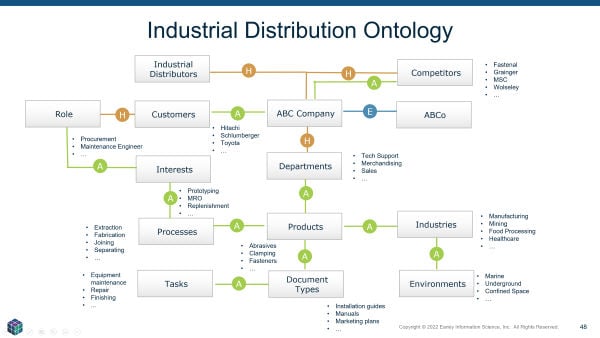
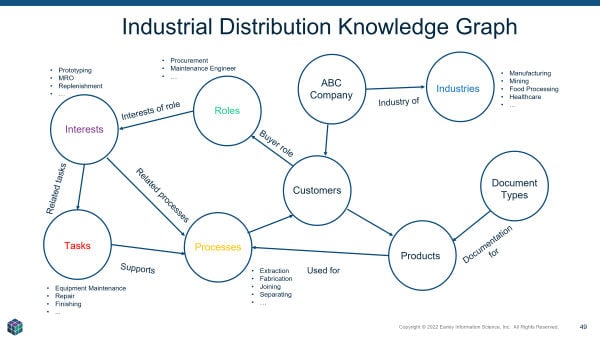
Ontologies provide knowledge, content, and data scaffolding. Overlaying this structure atop data sources produces knowledge graphs.
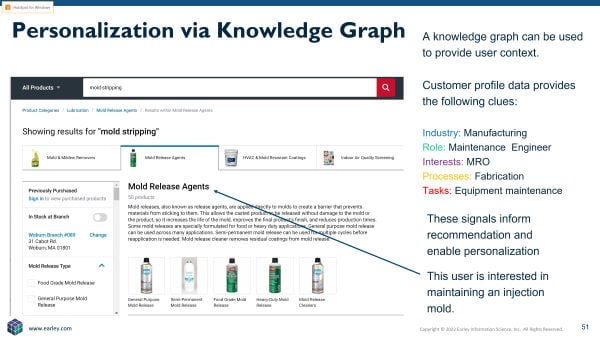
Consider users searching "mold stripping" on industrial distributor websites. Injection molding company employees likely seek supplies for mold breakdown. Real estate development company employees probably want mold and mildew removal solutions. Understanding interests, roles, processes, or industries provides signals surfacing correct products for specific users.
Definitional Framework
Taxonomies represent official terminology describing products, services, solutions, customers, documents, departments, markets—all business-critical concepts. Life sciences domains might include diseases, indications, drugs, drug targets, mechanisms of action with relationships like "indications for disease" or "drug targets for mechanism." Insurance domains encompass policy types, business classes, risks, operational regions with relationships such as "risks in region" or "policy type for business class."
Ontologies comprise all organizational domain taxonomies and inter-taxonomy relationships. Knowledge graphs combine ontologies with organizational data. Graph databases focus on connections rather than quantitative analyses typical of relational databases. Visualized relationship presentations reveal links between people, places, events, entities. Since relationship data resides in graph databases, analysis proceeds dramatically faster than traditional approaches requiring queries across multiple databases eliciting relationships.
Business Value Realization
Critical questions emerge: how do knowledge graphs produce measurable organizational value? Many projects stall here. They effectively handle data and content but struggle demonstrating returns.
Identifying hard ROI for data and infrastructure initiatives proves challenging. One organization invested $500,000 in knowledge graph work. When questioned about returns, the program leader stated no ROI existed—they simply needed starting. However, business cases and returns should justify even exploratory technology work. Organizations may explore tools without ROI as necessary research identifying new approaches and opportunities. However, use cases should justify experimentation. "Excuse cases" can justify investments potentially yielding additional benefits beyond primary objectives.
Customer Identity Graph Applications
Knowledge graphs collate customer interaction information across touchpoints, then leverage data improving user experiences. Organizations increasingly develop first-party data programs capturing profile information from interactions across channels, devices, touchpoints. Interaction data exhaust becomes knowledge graph inputs for customer interactions—identity graphs.
Knowledge graph advantages include mapping disparate data sources and structures. Identity graphs through customer data platforms or graph data platforms enable 360-degree customer interaction views and digital body language-based action.
Signal consolidation advantages include greater relationship insight when multiple divisions serve identical customers, cross-sell and upsell capabilities based on purchase history and service interactions, improved personalization and recommendations, and enhanced customer analytics efficiency.
Customer identity graph versions essentially provide attribute models. They supply customer-related information: content types, products, topics, process interests alongside purchase histories and organizational interaction patterns. Customer data platforms typically capture this data enabling real-time digital body language monitoring—the clues and details customers leave during organizational interactions.
Enterprise-Wide Transformation Support
Knowledge graphs serve multiple enterprise applications beyond personalization. They catalog structured data sources, provide disparate information integration mechanisms, and enable access methods contextualizing data with content and knowledge—connecting "what happened" with "why it happened."
Knowledge graphs additionally document data provenance, quality metrics, permitted usage, ownership, rights, governance, and change management processes. They enable data democratization improving visibility and appropriate access without jeopardizing policies. Using knowledge graphs for catalog and access management improves enterprise data visibility, enabling broader business stakeholder data utilization supporting business imperatives.
Knowledge graphs aren't silver bullets. They require disciplined data management practices and proper hygiene. They represent toolkit components supporting digital transformation program goals. Digital transformations fundamentally constitute data transformations. Building and maintaining enterprise ontologies and knowledge graphs provides data foundations determining transformation success.
The competitive landscape increasingly rewards organizations treating knowledge graphs strategically rather than opportunistically. Those integrating graph structures systematically across operations extract disproportionate value from data assets. Those implementing fragmented graph initiatives experience disappointing returns despite technology investments. The difference stems from treating knowledge graphs as foundational capabilities rather than isolated projects.
Investment approaches matter enormously. Organizations should begin with comprehensive ontology development establishing semantic foundations. Then systematically populate graphs with high-value data and content. Measure value through specific use case improvements rather than abstract infrastructure metrics. Build organizational capabilities maintaining graph quality and currency. Establish governance ensuring consistent taxonomy management and relationship modeling.
These investments compound over time. Initial ontology work enables first graph applications while creating reusable assets supporting subsequent implementations. Each application benefits from existing semantic frameworks rather than starting fresh. Organizations develop sustainable advantages through accumulating structured knowledge assets competitors cannot easily replicate.
This article was originally published on CustomerThink and has been revised for Earley.com.