When supported by an appropriate information architecture and designed with a deep understanding of the customer, virtual assistants can access enterprise knowledge efficiently, saving time and money. The key to success is to structure the underlying information so it can be retrieved and used by any channel, including humans, to deliver the responses that customers need.
What is omni-channel?
Omni-channel means more than just allowing a customer to purchase something either on the web or through a contact center; more than having a chatbot or an intelligent virtual assistant available. It means maintaining contact even when a user is switching devices, or when they begin a process on one channel and complete it on another. The handoffs should be smooth, and each channel be aware of the progress a customer has made in the previous channel. It means providing consistent information and messaging across all channels, whether to internal or external users. In order to create this consistent experience, however, a great deal of work must go on behind the scenes.
Omni-channel means maintaining contact even when a user is switching devices, or when they begin a process on one channel and complete it on another.
The information retrieval continuum
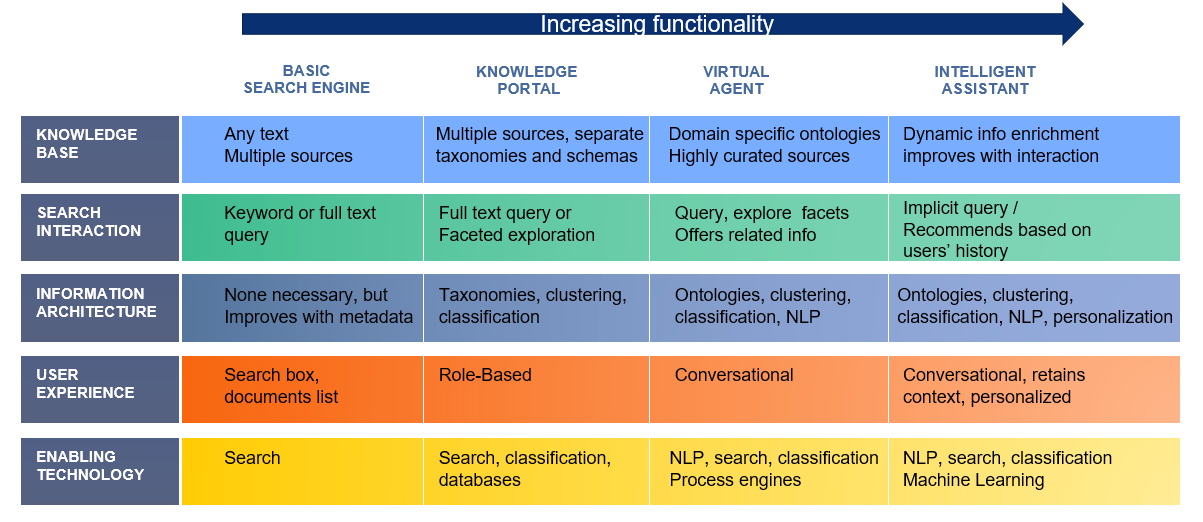
It is important not to overlook this fact: chatbots are simply another mechanism to retrieve information. Just like any other information retrieval mechanism, it requires certain data sources to create the interactions. Increasing levels of sophistication in information architecture allow for more nuances around the experience.
As the enabling technology moves from basic search (shown below in the lower left hand corner of the graphic) to more sophisticated levels such as classification and finally to natural language processing and machine learning, the user experience shifts from interacting with a simple search box to a personalized conversational experience. The required information architecture similarly moves from being non-existent or having just metadata, to taxonomies and ontologies, to a very sophisticated architecture that can support an intelligent virtual assistant.
Voice and text
When you are talking with someone on the phone, you get a lot more information than you do from the same words presented in text on a screen. Non-verbal information--the volume of speech, the pauses, interruptions, and voices speaking over each other can also convey information.
These signals contribute to being able to carry out sentiment analysis, which provides valuable guidance during an interaction. Key words can also provide insights for sentiment analysis, but audio is important for nuance. This nuance in turn guides a customer service representative to the next action.
If sentiment analysis is showing a poor interaction, then the next action might be different from the one selected during a positive interaction. Sometimes there might need to be a shift from an automated action to an in-person interaction. The downstream effects on brand and loyalty resulting from a poor interaction can be significant, so knowing how to turn a poor interaction into a good one makes a big difference.
Real-time speech recognition and intent classification
Although speech analysis can be valuable after the fact, real-time analysis is necessary for correcting actions on the spot. In addition it can help a human and a bot work together to determine intent. It's important to distinguish between two types of speech recognition: long form and short form. Long form is derived from extensive, unstructured conversation, and speech recognition followed by text analysis can be used effectively to analyze sentiment, identify concepts. Natural language processing is used for this, to extract keywords and themes.
Short form conversations are intent-based, bots in those conversations are looking for keywords for the purpose of driving a reaction or an action. The conversations occur when a customer is trying to solve a problem or make a decision. Sometimes bots can produce a suggestion, but they can also provide the agent with the next best action, based on previous data from other customers who had a successful outcome.
Structuring information for retrieval
All too often companies automatically jump to a solution space, and try to identify the right software to assist them, when they should start out with a foundation space. This means organizing the information they have, sometimes using taxonomies or ontologies. Sometimes companies do have taxonomies, but often there are many fragmented taxonomies, with no formal structure that puts them into an ontology that shows the relationships among them.
In addition, organizations often lack controlled vocabularies that help manage diverse terminology that may be used across or within departments. Building one uber-taxonomy is not necessary or even advisable, but the way in which the metadata from one maps to another is important in order to have a single version of the truth.
Using knowledge graphs and graph data can provide a very comprehensive picture of organizational knowledge. However, most organizations are very early in that learning curve.
Identifying high-value use cases
The best approach to starting out is to pick a high-value process for which you can see measurable results. Cherry pick your first use case, one where you know what the desired future state and have baseline metrics. Once you show ROI on a narrow set of use cases, then you can get more support for funding future initiatives.
One mistake a lot of organizations make is that they don't track the metrics, often because the people involved in the development of bots are so distributed. We recommend that organizations build metrics-driven change management and governance right from the start because that applies not just to the first group of use cases, but enterprise-wide.
Companies should monitor the digital body language of the user--what are customers actually doing across the different channels and devices. The use cases and different scenarios should be modeled, along with the actual tasks and then see how well they are supported by bots. Organizations should be building libraries of use cases that become the source of truth for any of the systems.
Moving from proof of concept to factory production
Consolidating efforts within an organization is critical to moving from experiments to broader implementation of an omni-channel strategy. Execution can take place in a decentralized way in different departments, but being able to manage the initiatives in a centralized way is far more efficient because you are not re-inventing the wheel, and allows for consistency across departments. Centralized management also allows for best practices to be more widely implemented than if the bots are developed in silos.
In order to scale up the production of bots, companies need to think about it from a factory approach. This stage builds on the investments the organization has made in content to ensure its usability. They need to be standardized so they can be consumed. In addition, many of the design elements of the bots can be standardized.
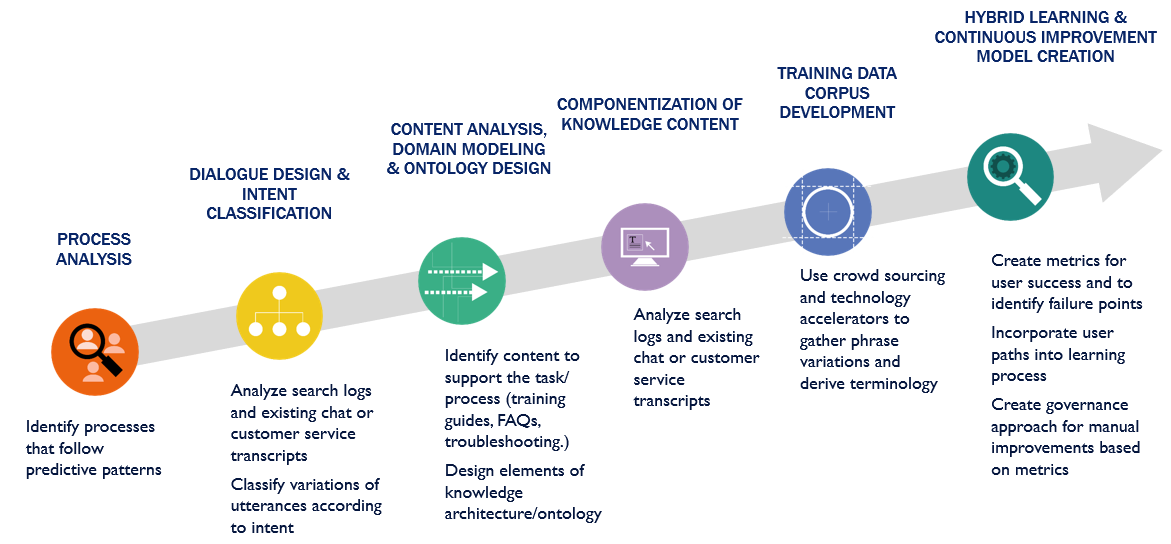
The graphic below shows the process required to develop a bot factory, beginning with identifying processes that follow a predictive pattern. The next step is to design dialogs and classify intent. At the top end of the scale is the ability to use metrics for continuous improvement.
 Conclusion
Conclusion
Omni-channel enterprise systems can be challenging to implement, but when all the channels can access reliable sources of well-curated data, they can provide the user with a consistent and positive experience. Analyzing spoken conversations for non-verbal clues provides organizations with additional insights beyond what is found in text-only content. Bots can serve multiple roles, interacting directly with customers or supporting customer service representatives by pro-actively delivering relevant information. Regardless of the role, bots need well organized content that can be searched quickly to provide users with the information they want.
Related: Omni-channel Virtual Assistants - The Next Frontier in Voice and Text for Customer Service.