Ontologies form the knowledge scaffolding of the enterprise and provide reference values for both structured and unstructured information. They consist of the various taxonomies that describe enterprise information (products, services, solutions, processes, business units, regions, roles, interests, document types, and more) along with the relationships between these elements. (Services for a product or solutions to problems, interests of a role and more) This is reference data - the official terms and labels for information) it is important because without it, your systems and technologies will not know the names of your products, terminology of your organization and processes that are powered by data. Large language models also require ontologies since they are trained on public data - not information from behind your firewall.
An ontology is a set of concepts and categories in a subject area or domain that shows their properties and the relations between them.
Knowledge bases are sources of truth for AI powered applications. Ontologies form the the structure on which knowledge is contextualized. Ontology-based AI allows the system to make inferences based on content and relationships and can produce personalized results by relating customer data to the products they would be most interested in.

Types of ontology knowledge models
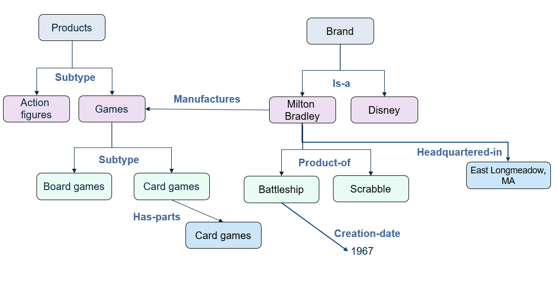
Knowledge models run along a continuum, beginning with the simplest level in which a controlled vocabulary is developed to encourage the use of the same word for a particular meaning (such as always using “client” rather than a mix of “client,” “customer,” and “purchaser”). The next step is a thesaurus, which allows identification of terms that relate to a single concept. The next stage is a taxonomy, which defines a hierarchy with parent-child relationships. The parent child relationship might be a specialization of a product category, or one item being classified as part of another, such as an engine being part of a car. They are often used as a navigational construct on websites to get the user from one piece of information to another. An ontology is a representation of the relationships among multiple taxonomies. Finally, a knowledge graph can be used to capture specific instances of the relationship, such as a particular sales transaction between entities, whereas the ontology is generic.
Ontology is therefore the knowledge scaffolding in an enterprise, and a lot of value can be achieved by leveraging that structure across multiple systems and data sources. Knowledge of relationships between concepts allows identification of solutions to problems, or knowledge about which products or services go with another set of products.
Types of relationships within the model
Different types of term relationships are applied to different knowledge models.
- Equivalence is used in thesauri, and it does not necessarily refer to synonyms. For example, transparency and opacity both refer to the same concept, although they describe it in different ways.
- Hierarchical relationships are used in taxonomies to categorize items or concepts, and associative terms are used for concepts or entities in ontologies.
- Associative terms are context- and audience-specific, and are used to relate multiple taxonomies to each other.
The figure below shows each of these in the context of game manufacturers. Once the ontology has been established, it becomes a very versatile tool. A brand manager might it to reveal one set of connections while a salesperson might use others, and a product developer still others.
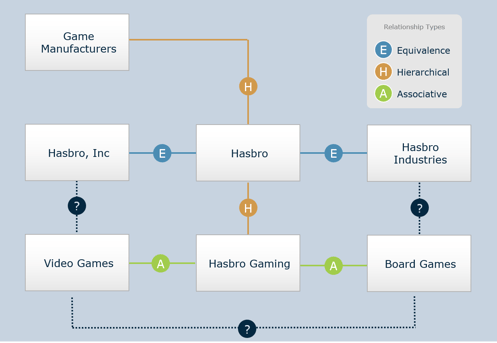
Ontologies and taxonomies have some elements in common, but ontologies provide a richer set of information. A taxonomy is a tree structure, and one item or concept can have only one parent. In an ontology, an object such as a smartphone can inherit features from multiple parents. This quality is useful because in the real world, objects and concepts are related to each other in many ways, not just in a single hierarchy.
As a simple example, two individuals might be identified as co-presenters in a conference session. A human could readily understand that both were presenting at the conference, but without a defined relationship between the two, a computer system could not. The use of ontologies allows a system to infer conclusions and answer unanticipated questions that have not been programmed into them. It functions as a Rosetta stone that allows systems to communicate with each other, providing a richer context and knowledge base.
One way to think of ontologies is that they are master data management (MDM) for AI, in that they provide an overall structure for knowledge, but they differ in that they are dealing with more than data. They could be dealing with workflows, business processes, and other constructs that are not present in data itself.
Ontologies must work with multiple systems in order for their value to be fully realized.
Knowledge of product relationships and solution relationships can be embedded--for example, the components needed for a product, and what alternate parts can be purchased. These can be added to the ontology, which becomes an asset of increasing value.
Ontology real world example
Ontologies can be applied to situations in which customer behavior is being assessed. The Cleveland Museum of Art wanted to understand its visitors’ preferences and patterns of interacting with the museum’s collection. In order to do this, they needed to identify the characteristics of the collections, their themes, locations, and specific points of interactions by visitors. Terminology was developed to represent locations because those were needed in order to set up the correlations between visitor reactions and the exhibits. Visitors opted in to allow the museum to record their utterances. An ontology was developed to connect geo-spatial data to behavioral analytics based on very specific pieces of content. The museum gained a better understanding of its visitors’ preferences and was able to offer an improved experience.
An ontology allows an enterprise to reuse existing knowledge and resources by breaking them up into components that can be fed into multiple systems and applications and sent to multiple consuming systems, such as Slack, Facebook or other user-selected interface. The repository needs to be very granular in order to bring back the precise piece of content that reflects what the user was looking for. Conversational commerce requires a semantic deconstruction of utterances in order to respond appropriately to the user.
Ontology and digital transformation
For a full digital transformation, the enterprise will need hundreds or thousands of AI projects, so setting the stage for scaling up is essential. Rather than having a series of disconnected projects, a repeatable framework should be developed. Moreover, with an ontology in place, changes can be made to the data in one location and propagate through the existing associative relationships. So if there is a change in the price of a service, for example, the system does not require re-coding in multiple applications; the data can be changed once and carry through to all of them.
A robust information architecture is required in order to support sophisticated solutions that are emerging as organizations move forward with their digital transformations. Ontologies provide a re-usable, adaptive structure for organizations that want to power their AI initiatives. The more detailed the ontology, the more meaningful will be the responses that users receive.