Struggling to differentiate between a business taxonomy and business ontology? Don’t worry, you’re not alone. This post breaks down the key differences and explains why each plays a critical role in organizing and maximizing the value of your business data, content, and knowledge. Get ready to take your information management skills to the next level!
What Is a Taxonomy?
In simplest terms, a taxonomy is a group of related things.
When you walk into a large home improvement store with a shopping list, how do you know where to go?
First, you consider the department you need to visit. Do you need appliances, electrical, hardware, building supplies, paint, or plumbing? When you reach the department, you find the aisle that holds the product you need.
Without realizing it, you accessed your internal mental model of home improvement categories to find what you need. The department and product categories are taxonomies.
Why does it matter? Humans organize and categorize things so we can find them later. At its core, a taxonomy exists to help us store and retrieve information.
To better understand the nature of a business taxonomy, let’s explore a scenario. I’m opening a small, local hardware store. The store will have the following departments:
- Lumber
- Tools
- Hardware
- Electrical
- Plumbing
What about paint, appliances, home and garden, and all the other departments found at big-box retailers? I don’t intend to stock those categories, so I omit them. A business taxonomy should include only the items needed to support your business.
Within a department, I have a product taxonomy. Here’s an excerpt from the Tools taxonomy:
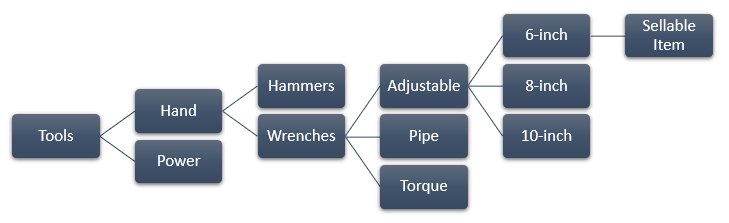
Notice the multiple levels of hierarchy. Categories enable users to navigate or filter down to a product that meets their requirements, which is a sellable part number.
What if I want to create shopping lists to help my customers prepare for popular home projects or repairs? That brings us to the limits of a taxonomy. Taxonomies define categories within a single domain. In this case, the product domain. A taxonomy can’t connect to other domains on its own. That’s a job for an ontology.
How Is an Ontology Different from a Taxonomy?
An ontology captures multidimensional relationships. It connects taxonomies to provide rich information about the business environment.
Let’s return to my local hardware store and the idea of creating shopping lists for popular home projects. Which entities and relationships do I need to understand?
- Which popular projects do I want to support?
- Which materials are needed to complete each project?
- Finally, I must confirm that my store can fulfill all items in each Materials List instance.
Here’s a visual representation of the resulting ontology:
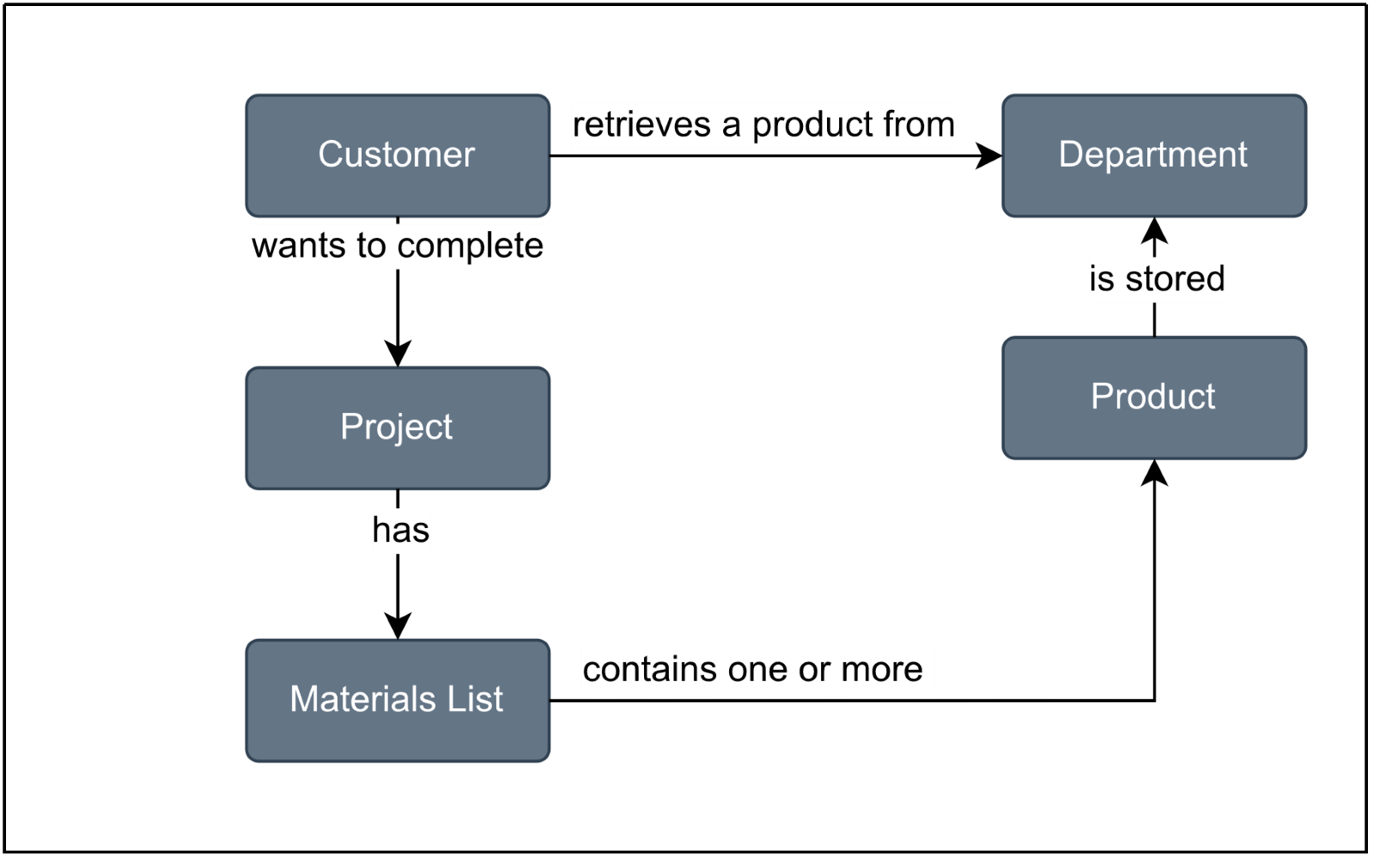
Each box is an entity in the ontology. The arrows represent the relationships among entities, where each label describes the specific nature of that relationship.
Notice that this simple ontology depends on previously defined taxonomies. But merely creating a set of taxonomies does not mean you have an ontology.
The interrelationships among the entities in the taxonomy are the essence of the ontology. Therefore, the ontology reflects a broad view of the business and a detailed description of its components.
Relationships in ontologies sometimes change depending on the context. Whereas a taxonomy is defined and static, ontological connections are dynamic. For example, if we offered seasonal items in the hardware store, selecting fall versus winter changes the product list from rakes to snow shovels. A relationship may be active in one situation and inactive in another. One choice can trigger others.
Why Businesses Need Ontologies
An ontology is the key to delivering personalized, low-friction customer experiences. Ontologies contextualize business data to fuel targeted marketing campaigns, personalized content experiences, and intelligent virtual assistants and bots.
Let’s revisit my hardware store ontology for examples. The ontology reveals relationships beyond the product domain that can make my hardware store more customer-centric.
Consider the characteristics of potential customers. Can you think of categories of people who might be interested in a smaller, local hardware store?
- Homeowners
- Building maintenance workers
- Craftworkers and tradespersons
- Plumbers
- Electricians
- Carpenters
When we segment customers like this, we can design targeted marketing campaigns that are more likely to succeed. We can offer the professionals trade-specific product recommendations if we understand the relationship between the products and trades.
What about homeowners and maintenance workers? How can we cater to them?
Imagine you’re a customer who needs to complete a home repair. You visit my hardware store’s website, and a chatbot asks, “What do you want to do?” followed by a list of popular home projects and repairs. The taxonomy includes tasks like building a deck, installing a ceiling fan, and replacing a toilet, among others.
You select “Replace a toilet.” Behind the scenes, the ontology supplies the semantic layer to retrieve relevant information and send it to the website’s front end for presentation. Now, you can browse the brands, compare features, and generate a list of project materials.
If you want to build a deck, select that choice and see a materials list that includes supporting posts, decking lumber, deck screws, and a circular saw. You have a circular saw but need everything else. Add those items to your online cart, pay, and schedule a curbside pick-up for tomorrow morning.
Sounds easy, right? Much like building a deck, ontologies can be challenging to build.
Why Ontologies Are Challenging to Develop
It’s rare for one person to have all the business and customer knowledge needed to develop an ontology. Engaging and coordinating subject matter experts who collectively hold this knowledge is often time-consuming.
Professional information architects begin with expert interviews to create a domain model that names the entities in the business. They dig into the interactions between entities to uncover relationships and dependencies.
While we want a comprehensive list of potential connections across the business, it’s easy to overdo it.
If the ontology doesn’t capture the necessary entity relationships, the results will be inconsistent or incorrect. When the ontology is more detailed than you need, development takes longer, and the ontology is more challenging to navigate. You want to find the balance of “just enough” to meet your business goals.
Finally, there’s the language of your ontology. How does the business talk about itself and its products or services? What language do customers use? Does it vary by geographic location or other factors? What about technical terms, synonyms, alternative spellings, translations, and acronyms? The language must make sense to users.
Is an Ontology Worth It?
If your business needs to deliver exceptional customer experiences, adopt AI (Artificial Intelligence) technologies or automate business processes without a doubt!
While you should have a long-term roadmap for an enterprise-wide initiative, you can tackle ontology development in stages. Start with one function, such as marketing or customer support. After you prove the value in that area, move on to the next.
Finally, be relentlessly practical with your approach. It’s easier to expand a minimal ontology than to reduce a highly detailed, very granular ontology.
