Organizations are paying more and more attention to Master Data Management (MDM). MDM comprises a set of processes and tools that consistently defines and manages the both the transactional and non-transactional data entities of an organization related to a particular domain, such as purchases or product information and customer data. It connects all an organization’s critical data, which is generally scattered across numerous systems throughout an enterprise, and reconciles inconsistencies, duplication and missing data. MDM initiatives are a critical part of data transformations.
A master data taxonomy is the structure that feeds and organizes this master data. For example, a product hierarchy and product categories might be defined in an Enterprise Resource Planning (ERP) system, which then feeds other downstream applications such as ecommerce sites that need product data. Customer data may be scattered across many different systems that do not all use the same terminology or metadata. MDM integrates and normalizes this data.

According to a study by Aberdeen, companies using MDM are more than twice as likely to be satisfied with data quality and speed of delivery, compared to those not using master data management. The report notes that with well organized data, users can find the information they need more quickly, which leads in turn to faster decision making and operational efficiency.
Master data depends on reference data from a taxonomy. For example, the master data for a customer record is stored in a “golden record” which could be in a customer relationship management system (CRM) or an ERP. An enterprise taxonomy would provide the attribute values such as industry, customer type, role, interests and other descriptors that would enable classification of customers so that the correct content can be served up as they use a web site.
Content classification and customer classification are important components to personalization initiatives, and they depend on a consistent taxonomy across all customer touchpoints and the multiple systems that comprise the customer experience. Content management systems require the same taxonomies and master data that a CRM requires in order to surface content in context for the user. MDM is the method for providing this over-arching structure that supports multiple systems.
Content, customer, and product classification are especially important for the digital transformations that every organization is now planning or executing. The increasing use of artificial intelligence (AI) also means that a source of truth as reference and master data driven by taxonomy is even more important. AI applications do not know what is important to the organization. Taxonomy and master data tell the AI the names of products, services, customer types, content, knowledge and more.
MDM promises not just greater control over consistent reference data, but an ability to manage the relations between data entities in order to generate more effective business knowledge. From this perspective, MDM requires an understanding and agreement about the meaning of terminology. Hence, the natural role of taxonomy. Taxonomy is about "semantic architecture." It is about naming things and making decisions about how to map different concepts and terms to a consistent structure. Data governance is required to support these decisions and to maintain an enterprise taxonomy with consistent data standards.
MDM challenges and the argument for data taxonomy
Ambiguity . The same term can have different meanings. Taxonomy provides a hierarchy that helps remove ambiguity. It includes mechanisms for understanding context and making meaning precise.
Consistency . Obtaining complete agreement on what terms to use can be difficult. Also, people often use terms inconsistently. Sometimes the terms used in legacy applications differ from those used in newer systems. For various reasons the data sometimes can't be re-tagged to provide consistent metadata. A thesaurus can map terms together to account for these inconsistencies but the mapping needs a set of structures to create these relationships and support data harmony.
Connections . Taxonomies can also represent related concepts (technically also part of a thesaurus) that can be used to connect processes, business logic, or dynamic/related content to support specific tasks.
An MDM strategy defines the process for data cleansing, harmonizing the attributes, and ensuring that all required information is present.
However, MDM programs also need to leverage taxonomy, and taxonomy should make use of MDM initiatives. The two methodologies are symbiotic.
- Although taxonomy is typically applied to unstructured content, it is increasingly supporting both structured and transactional content - a data taxonomy.
- Similarly, master data plays an essential role in making unstructured information consistent, findable, and valuable.
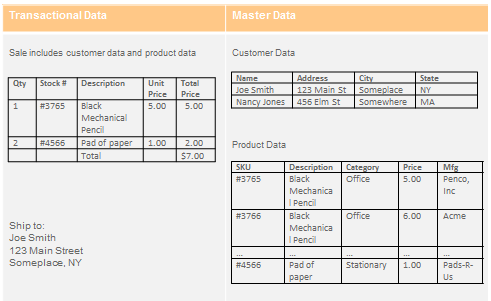 Let's look at the product master.
Let's look at the product master.

Consider two different manufacturers that both offer mechanical pencils. In our product master, they are called the same thing. However the original product manufacturers do not necessarily use the same terms to describe their products. The original bills of lading might have used abbreviations that are not easily understood, for example. Or the attributes may not be consistently described” or reflected in the metadata. In one case the metadata label may be “customer” and in another, it may be “client.
One manufacturer classifies their product as Stationary and other calls it Home Office. Further, one abbreviates the attribute of Color as Bl and the other uses Blk. With these inconsistencies, it is impossible to deliver an excellent user experience where this data may need to be displayed.
Bringing it all together with taxonomy and master data management
MDM fixes these inconsistencies by improving data quality . Although each supplier has a way or organizing and describing their products that may or may not be aligned and consistent, the retailer needs to drive a consistent user interface and experience to achieve the best business outcomes. The system needs to have the following characteristics:
- A centralized repository where "the source of truth" exists
- Governance processes for fixing inconsistencies or providing feedback to suppliers
- Rules for automating remediation of predictable inconsistencies
- Tools for cleansing and normalizing the data (running scripts and converting the data)
The role of a data taxonomy is even more important in multi-domain MDM, which is the direction in which the industry is heading. According to Gartner, 58% of the reference customers in its 2018 Magic Quadrant Report on Master Data Management Solutions are facing the requirement for multi-domain MDM.
Whereas in the past, most MDM systems were focused on a single area such as product data or customer data, more organizations now want to bring data together from multiple domains, to allow for a broader range of business use cases and greater use of analytics. [After reading this, it seemed that it should be made clearer the beginning of the article that “basic” MDM is only integrating one area so I went back and made some suggestions about that.]
In order to conduct analyses across domains and develop effective governance programs, organizations need to set up consistent taxonomies and standard metadata, especially on their critical data. The data models will need to reflect a consistent taxonomy. Ultimately, the relationships among different taxonomies should be captured and documented through an ontology, but having an MDM with appropriate taxonomies is a good foundational step to take.
Nothing about this is easy (or sexy) but it needs to be done if your initiatives are going to make headway. Our team of information science experts can help. Give us a shout if you'd like to talk .