This is Part 2 of a two-part series. Read Part 1: Structure Before Speed: Why Enterprise AI Needs Information Architecture First.
Organizations that invest seriously in information architecture tend to hit a recognizable plateau. Retrieval-augmented generation improves. Hallucinations decrease. User satisfaction climbs. Then progress stalls. The system retrieves better documents but reasoning remains shallow. It summarizes competently but stumbles when policies conflict. It answers questions but cannot act reliably across domains.
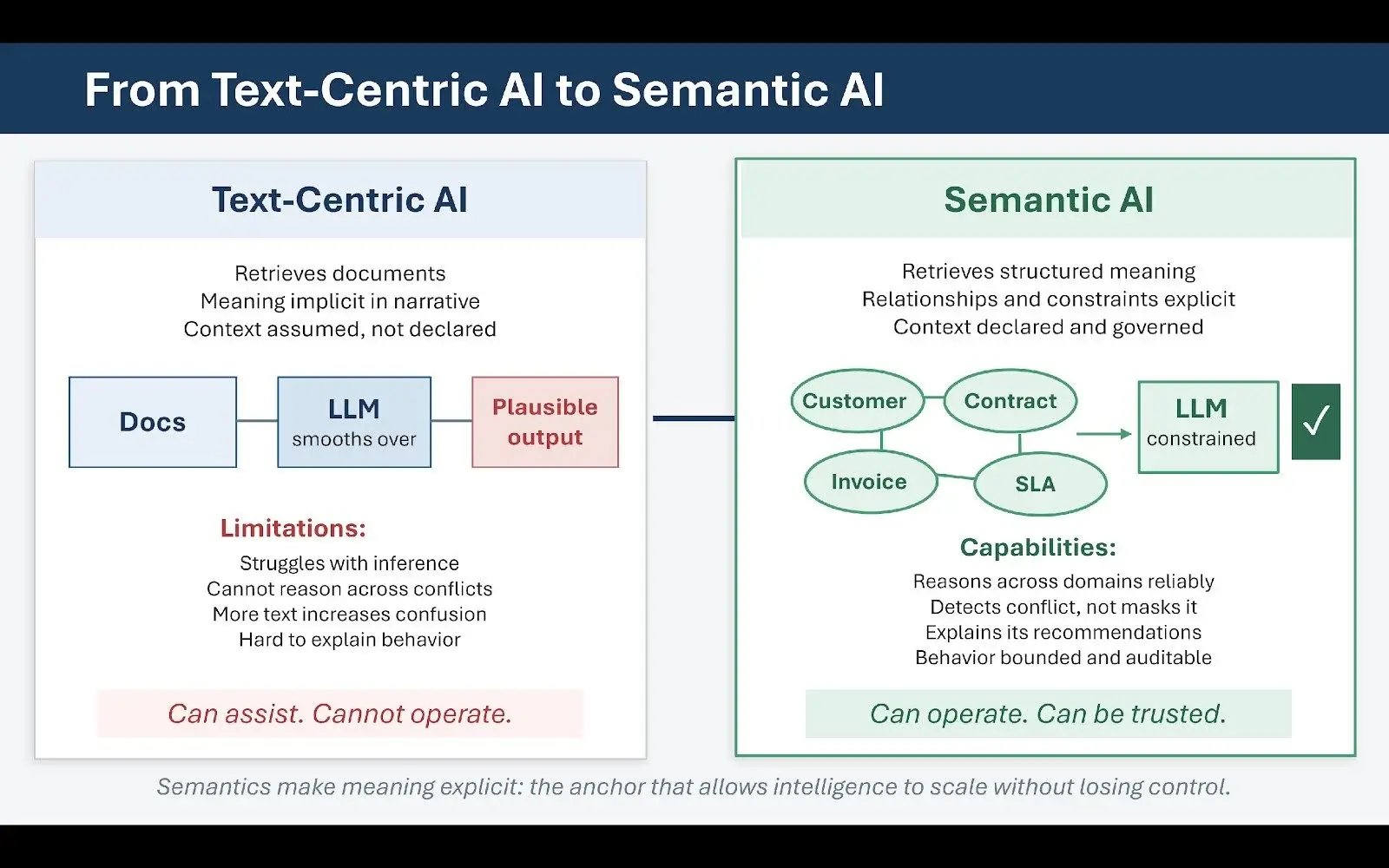
This plateau is not a model failure. It is the limit of text-centric intelligence.
Retrieval-augmented generation, at its core, retrieves documents. Even when retrieval is precise, documents remain narrative artifacts that encode meaning implicitly rather than explicitly. They assume shared context. They carry accumulated compromises, exceptions, and historical drift that are legible to experienced humans but opaque to machines. Language models are extraordinarily good at smoothing over this ambiguity — which is simultaneously their greatest capability and their greatest risk. When confronted with inconsistent or conflicting information, the model produces plausible synthesis rather than structural resolution. In regulated industries, plausible synthesis without traceability is not intelligence. It is liability.
What Semantics Make Possible
Semantics are the answer to the problem that better retrieval cannot solve. Where retrieval improves what a system can find, semantics clarify what the system actually understands. They encode relationships, constraints, and distinctions that text cannot reliably convey on its own. They answer the questions that documents assume rather than state: What distinguishes a customer from a prospect? How does a policy exception relate to a standard rule? What conditions trigger escalation? Which product configurations are mutually compatible?
Knowledge graphs, controlled vocabularies, and ontologies provide this explicit semantic layer. What is genuinely new about their role in today's enterprise AI landscape is not the technologies themselves — these have existed for decades — but their function as governance mechanisms for intelligent systems. In agentic environments, semantics provide the control surface that determines what can be inferred, what cannot, and under what conditions autonomous action is appropriate. They make reasoning inspectable and constrain interpretation in ways that allow behavior to be audited rather than simply observed. Without semantics, agent behavior is emergent and difficult to explain. With semantics, it becomes bounded and accountable.
Reasoning Across Domains Requires Explicit Relationships
A straightforward example makes the distinction concrete. Consider a customer inquiry that spans billing records, contract terms, and service history. Each domain may be thoroughly documented within its own system. But the relationships between them — which contract governs which invoice, which service levels were active during a given period, which exceptions were approved and when — are rarely explicit in the text of any individual document.
A language model can retrieve content from each domain and produce a fluent, seemingly responsive answer. But without explicit semantic relationships, it cannot reason reliably across those domains. It will infer, sometimes correctly, sometimes not, and the difference between those outcomes will not always be visible until consequences emerge.
A knowledge graph makes those cross-domain relationships explicit. It encodes entities, attributes, and connections. It defines what constitutes authority. It allows reasoning to proceed along known paths rather than speculative ones. This does not diminish the role of language models — it changes it. In mature systems, language models operate within a semantic frame rather than across an undifferentiated corpus. They generate explanations and recommendations constrained by explicit structure. This combination of semantic precision and generative fluency produces a fundamentally different class of system: not merely helpful, but dependable.
Why More Text Does Not Produce Better Reasoning
This distinction also addresses a persistent misconception about retrieval-augmented generation. Many organizations assume that better embeddings, larger context windows, or more aggressive chunking strategies will eventually solve reasoning problems. These techniques improve retrieval quality, but they do not resolve semantic ambiguity. They retrieve more text without clarifying meaning. As organizations scale agentic systems, they frequently discover that adding more content increases confusion rather than reducing it. Contradictions surface, edge cases multiply, and prompts grow increasingly elaborate in an attempt to compensate for the underlying structural gaps.
Semantics reverse this dynamic. They reduce the text burden by externalizing meaning explicitly, allow prompts to reference well-defined concepts rather than restate assumptions at length, and enable knowledge reuse across use cases. This is why organizations that once dismissed knowledge graphs as too heavy or too complex are revisiting them — not as analytics tools or visualization infrastructure, but as foundational governance mechanisms for AI at scale.
Governing Meaning: Semantic Stewardship
A critical point is often missed in discussions of semantic architecture: the goal is not a perfect model of organizational reality. It is a sufficiently shared model to align behavior. An ontology does not need to capture every nuance to be useful. It needs to capture enough to make agent behavior predictable and auditable.
Many semantic initiatives fail not from insufficient ambition but from excessive scope. Teams attempt to model everything, complexity explodes, adoption stalls, and the resulting artifact becomes a documentation exercise rather than a functioning governance tool. Successful initiatives start with core entities and the highest-value relationships, evolve iteratively, and are governed continuously as the business changes.
That continuous governance dimension is essential. Semantics are not static. Business models shift, regulations evolve, new products are introduced, and the meaning of established terms drifts. In agentic systems, semantic drift carries the same operational risk as model drift. If definitions change without coordinated updates, agents will act on outdated assumptions with full confidence. Semantic stewardship — the ongoing discipline of monitoring, managing, and updating shared meaning — is not a project with a completion date. It is an operational function.
From Assistance to Operation
When this is done well, the transformation in system capability is substantial. Agents operating over semantic infrastructure can reason across domains without improvisation, detect conflict rather than paper over it, explain the basis for a recommendation, and surface uncertainty rather than masking it with confident language. This changes the nature of human-machine interaction in a meaningful way. Rather than asking "Is this answer right?" users can ask "Why did the system reach this conclusion?" That shift is the foundation of genuine organizational trust in AI systems.
It also enables more sophisticated orchestration. Agents can assess when to act autonomously and when to escalate. They can detect when operating constraints have been violated and defer when authority is ambiguous. These are not emergent properties of large models. They are designed outcomes of semantic architecture. Text-centric AI can assist. Semantic AI can operate. That distinction becomes the defining competitive variable as organizations mature their agentic capabilities.
The Governance Problem Organizations Keep Deferring
By the time organizations have made meaningful progress on information architecture and semantic infrastructure, the dominant challenges become organizational rather than technical. Models can be tuned. Retrieval can be improved. Semantics can be formalized. But without changes to governance structures and operating models, progress on each of these fronts eventually stalls.
The pattern is consistent: organizations accumulate successful proofs of concept, develop engaged vendor relationships, and cultivate internal champions. Yet each new agent deployment feels bespoke, each domain requires special handling, and lessons learned in one area fail to transfer cleanly to others. The underlying problem is not capability. It is ownership.
Agentic systems force a question that organizations have long managed to defer: who is accountable for meaning, behavior, and outcome when machines act on behalf of the enterprise? Traditional accountability was distributed implicitly. Business units owned processes, IT owned systems, and governance intervened episodically — typically in response to incidents. This arrangement worked because humans remained the ultimate decision-makers and could compensate informally for gaps in formal definition. Agents disrupt this balance. When a system makes recommendations, triggers downstream actions, or communicates externally, accountability must be explicit. Ambiguity that human judgment could previously absorb becomes operational and reputational risk.
New Roles for Distributed Intelligence
Organizations that successfully scale agentic capabilities respond by evolving their operating models around this accountability requirement. New roles emerge not as bureaucratic additions but as structural responses to the reality of distributed machine intelligence. Knowledge product owners take responsibility for semantic integrity within defined domains. Semantic stewards manage taxonomies, ontologies, and metadata as living operational assets rather than static documentation. AI governance leads oversee agent behavior, define escalation pathways, and maintain compliance with policy and regulatory requirements.
Without these roles, agents become orphaned capabilities — technically functional but organizationally unmoored, without anyone accountable for the quality of their outputs or the currency of the knowledge they draw on. With them, agents become managed participants in enterprise workflows, subject to the same accountability structures that govern human decision-making.
Bounded Autonomy as Governing Principle
The governing design principle for mature agentic systems is bounded autonomy. Bounded autonomy is not a constraint on AI capability. It is a recognition that not all decisions should be automated and that not all uncertainty can be resolved algorithmically. It means designing explicit thresholds for confidence, authority, and escalation — systems that know when to act and when to stop, that surface uncertainty rather than masking it, and that defer to human judgment when consequences exceed predefined bounds.
Information architecture enables bounded autonomy by providing the signals that governance relies on. Provenance establishes authority. Semantics clarify scope. Metadata encodes the context necessary for a system to assess its own confidence meaningfully. Together, they allow systems to know when they are operating within safe bounds and when they are not. This is why governance cannot be retrofitted after agents are deployed. It must be designed into the architecture from the beginning.

Figure 2: Bounded Autonomy: The Architecture of Safe Agent Behavior
Designing for Recoverable Failure
Another characteristic of organizationally mature agentic enterprises is how they think about failure. Agents will produce errors. Models will hallucinate on edge cases. Retrieval will miss context. Unanticipated situations will surface. The question is not whether failure occurs but how it manifests and how it is contained.
In poorly architected systems, failure is silent and cumulative. Errors propagate before anyone notices, root causes are difficult to trace, and trust erodes gradually before collapsing suddenly. In well-architected systems, failure is detectable, traceable, and recoverable. The system knows what it does not know, logs the sources behind its decisions, and allows humans to audit reasoning after the fact. Provenance links outputs to authoritative sources. Semantics localize errors to specific assumptions that can be corrected. Governance defines remediation pathways that prevent individual failures from cascading.
This is not accidental. It is the result of deliberate architectural design, and it is what separates organizations that maintain durable trust in their AI systems from those that oscillate between enthusiasm and crisis.
Scaling Through Discipline
The difference between organizations that move beyond isolated successes and those that remain perpetually in pilot mode is not technological sophistication. It is institutional readiness. Organizations that successfully scale agent capabilities treat intelligence as infrastructure. They invest in shared foundations rather than isolated point solutions. They standardize retrieval and orchestration patterns. They enforce semantic reuse across domains. They measure retrieval quality continuously, not just model accuracy.
They also resist the pressure to pursue novelty for its own sake. Rather than attempting to deploy agents everywhere simultaneously, they focus on the domains where structural foundations already exist or can be efficiently established. Each deployment strengthens the underlying architecture, making the next deployment faster and more reliable. The approach requires patience. It produces results that are durable rather than dramatic.
Over time, something important and largely invisible happens. The enterprise stops talking about AI projects and starts talking about how work gets done. Intelligence becomes embedded in operational processes rather than exceptional to them. Agents recede into the background, noticeable primarily when they surface useful insight or handle complexity with precision. This is the true mark of agentic maturity — not the number of agents deployed, but the degree to which their operation has become unremarkable.
The Architecture That Defines the Agentic Enterprise
The enterprises that lead in the agentic era will not be defined by the scale of their model investments or the sophistication of their interfaces. They will be defined by the coherence of their knowledge and the discipline of their architecture. Search, metadata, knowledge graphs, governance, and orchestration will converge into a unified cognitive infrastructure. Agents will operate atop that infrastructure not as replacements for human judgment but as extensions of organizational intent — amplifying coherence where structure is strong, and exposing gaps where it is not.
The principle that frames this entire series holds, and will continue to hold as models improve and technology evolves: no AI without information architecture. No agents without semantic foundations. No transformation without governance. Information architecture gives intelligence something reliable to stand on. Semantics give it the precision to act. Governance gives it the boundaries that make autonomy trustworthy. Together, these define the architecture of an enterprise where AI scales without losing control.
Read the original version of this article on VKTR.